The two components in JBossCache, plain cache (implemented as TreeCache) and PojoCache (implemented as PojoCache), are both in-memory, transactional, replicated, and persistent. However, TreeCache is typically used as a plain cache system. That is, it directly stores the object references and has a HashMap-like Api. If replication or persistency is turned on, the object will then need to implement the Serializable interface. In addition, it has known limitations:
- Users will have to manage the cache specifically; e.g., when an object is updated, a user will need a corresponding API call to update the cache content.
- If the object size is huge, even a single field update would trigger the whole object serialization. Thus, it can be unnecessarily expensive.
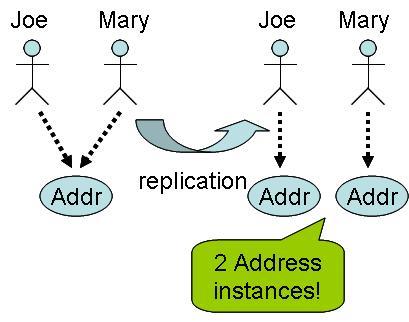
- The object structure can not have a graph relationship. That is, the object can not have sub-objects that are shared (multiple referenced) or referenced to itself (cyclic). Otherwise, the relationship will be broken upon serialization. For example, Figure 1 illustrates this problem during replication. If we have two Person instances that share the same Address , upon replication, it will be split into two separate Address instances (instead of just one).
PojoCache, on the other hand, is a fine-grained "object-oriented" cache. By "object-oriented", we mean that PojoCache provides tight integration with the object-oriented Java language paradigm, specifically,
- no need to implement Serializable interface for the POJOs.
- replication (or even persistency) is done on a per-field basis (as opposed to the whole object binary level).
- the object relationship and identity are preserved automatically in a distributed, replicated environment. It enables transparent usage behavior and increases software performance.
In PojoCache, these are the typical development and programming steps:
- Declare POJO to be "prepared" (in Aop parlance) either through an external xml file (i.e., jboss-aop.xml), or through annotation inside the POJO. Depending on your preference, you can either pre-instrument your POJO (compile time) or have JBossAop do it at load time.
- Use putObject Api to put your POJO under cache management.
- Operate on POJO directly. Cache will then manage your replication or persistency automatically.
More details on these steps will be given in later chapters.
PojoCache also extends the functionality of TreeCache to object based. That is, the TreeCache features such as transaction, replication, eviction policy, and cache loader, has been extended to POJO level. For example, when you operate on a POJO (say, pojo.setName()) under a transaction context, it will participate in that transaction automatically. When the transaction is either committed or rolled back, your POJO operations will act accordingly.
Finally, PojoCache can also be used as a plain TreeCache . For example, a user can use the TreeCache API [e.g., get(String fqn) and set(String fqn, String key, String value) ] to manage the cache states. Of course, users will need to consider the extra cost (albeit slight) in doing this.
Here are the current features and benefits of PojoCache:
Fine-grained replication. The replication mode supported is the same as that of the TreeCache: LOCAL , REPL_SYNC , and REPL_ASYNC. The replication level is fine-grained and is done automatically once the POJO is mapped into the internal cache store. When a POJO field is updated, a replication request will be sent out only to the node corresponding to that modified attribute (instead of the whole object). This can have a potential performance boost during the replication process; e.g., updating a single key in a big HashMap will only replicate the single field instead of the whole map! Please see the documentation of JBossCache for more details on cache mode.
Transaction. The POJO operation can be transacted once a TransactionManager is specified properly. Upon user rollback, it will rollback all POJO operations as well. Note that the transaction context only applies to the node level though. That is, in a complex object graph where you have multiple sub-nodes, only the nodes (or fields) accessed by a user are under transaction context. To give an example, if I have a POJO that has field references to another two POJOs (say, pojo1 and pojo2). When pojo1 is modified and under transaction context, pojo2 is not under the same transaction context. So you can start another transaction on pojo2 and it will succeed.
In addition, fine-grained operation (replication or persistency) under transaction is batched. That is, the update is not performed until the commit phase. And if it is rolled back, we will simply discard the modifications.
Eviction policy. PojoCache supports eviction policy that can evict the whole POJO object (and any field object references, recursively). Currently there is an eviction policy class called org.jboss.cache.aop.eviction.AopLRUPolicy (that is sub-class of org.jboss.cache.eviction.LRUPolicy ). The configuration parameters are the same as those of the TreeCache counterpart. Note that the concept of "Region" in eviction needs to be carefully defined at the top of the object FQN level. Otherwise, eviction policy will not operate correctly. That is, since "Region" is used to define the eviction policy, if you define a "Region" inside a POJO sub-tree, it may not be desirable.
Object cache by reachability, i.e., recursive object mapping into the cache store. For example, if a POJO has a reference to another advised POJO, PojoCache will transparently manage the sub-object states as well. During the initial putObject() call, PojoCache will traverse the object tree and map it accordingly to the internal TreeCache nodes. This feature is explained in full details later.
Object reference handling. In PojoCache, multiple and recursive object references are handled automatically. That is, a user does not need to declare any object relationship (e.g., one-to-one, or one-to-many) to use the cache. Therefore, there is no need to specify object relationship via xml file.
Automatic support of object identity. In PojoCache, each object is uniquely identified by an internal FQN. Client can determine the object equality through the usual equal method. For example, an object such as Address may be multiple referenced by two Persons (e.g., joe and mary). The objects retrieved from joe.getAddress() and mary.getAddress() should be identical.
Finally, a POJO can be stored under multiple Fqns in the cache as well, and its identity is still preserved when retrieved from both places (after replication).
Inheritance relationship. PojoCache preserves the POJO inheritance hierarchy after the object item is stored in the cache. For example, if a Student class inherits from a Person class, once a Student object is mapped to PojoCache (e.g., putObject call), the attributes in base class Person is "aspectized" as well.
Support Collection classes (e.g., List, Set, and Map based objects) automatically without declaring them as aop-enabled. That is, you can use them either as a plain POJO or a sub-object to POJO without declaring them as "aspectized". In addition, it supports runtime swapping of the proxy reference as well.
Support pre-compiling of POJOs. The latest JBossAop has a feature to pre-compile (called aopc, so-called compile-time mode in JBossAop) and generate the byte code necessary for AOP system. By pre-compiling the user-specified POJOs, there is no need for additional declaration file (e.g., jboss-aop.xml ) or specifying a JBossAop system classloader. A user can treat the pre-generated classes as regular ones and use PojoCache in a non-intrusive way.
This provides easy integration to existing Java runtime programs, eliminating the need for ad-hoc specification of a system class loader, for example. Details will be provided later.
POJO needs not implement the Serializable interface.
Support annotation usage. Starting from release 1.2.3, PojoCache also supports declaration of POJO through annotation under JDK1.4. JBossAop provides an annotation precompiler that a user can use to pre-process the annotation. As a result, there will be no need for jboss-aop.xml file declaration for POJOs, if annotation is preferred. The JDK5.0 annotation will be supported in the next release.
Ease of use and transparency. Once a POJO is declared to be managed by cache, the POJO object is mapped into the cache store behind the scene. Client will have no need to manage any object relationship and cache contents synchronization.
To use PojoCache, it is similar to its TreeCache counter part. Basically, you instantiate a PojoCache instance first. Then, you can either configure it programmatically or through an external xml file. Finally, you call the cache life cycle method to start the cache. Below is a code snippet that creates and starts the cache through an external xml file:
cache_ = new PojoCache(); PropertyConfigurator config = new PropertyConfigurator(); // configure tree cache. config.configure(cache_, "META-INF/replSync-service.xml"); // Search under the classpath cache_.start(); ... cache_.stop();
PojoCache is currently supported on both JDK1.4 and JDK50. For JDK1.4, it requires the following libraries (in addition to jboss-cache.jar and the required libraries for the plain TreeCache) to start up:
Library:
- jboss-aop.jar. Main JBossAop library.
- javassist.jar. Java byte code manipulation library.
- trove.jar. High performance collections for Java.
- qdox.jar. Javadoc parser for annotation.
For JDK5.0, in addition to the above libaries, you will need to replace jboss-cache.jar with jboss-cache-jdk50.jar and jboss-aop.jar with jboss-aop-jdk50.jar from lib-50 directory.