The TreeCache can be configured to be either local (standalone) or clustered. If in a cluster, the cache can be configured to replicate changes, or to invalidate changes. A detailed discussion on this follows.
Local caches don't join a cluster and don't communicate with other nodes in a cluster. Therefore their elements don't need to be serializable - however, we recommend making them serializable, enabling a user to change the cache mode at any time.
Replicated caches replicate all changes to the other TreeCache instances in the cluster. Replication can either happen after each modification (no transactions), or at the end of a transaction (commit time).
Replication can be synchronous or asynchronous . Use of either one of the options is application dependent. Synchronous replication blocks the caller (e.g. on a put()) until the modifications have been replicated successfully to all nodes in a cluster. Asynchronous replication performs replication in the background (the put() returns immediately). TreeCache also offers a replication queue, where modifications are replicated periodically (i.e. interval-based), or when the queue size exceeds a number of elements, or a combination thereof.
Asynchronous replication is faster (no caller blocking), because synchronous replication requires acknowledgments from all nodes in a cluster that they received and applied the modification successfully (round-trip time). However, when a synchronous replication returns successfully, the caller knows for sure that all modifications have been applied at all nodes, whereas this may or may not be the case with asynchronous replication. With asynchronous replication, errors are simply written to a log. Even when using transactions, a transaction may succeed but replication may not succeed on all TreeCache instances.
Buddy Replication allows you to suppress replicating your data to all instances in a cluster. Instead, each instance picks one or more 'buddies' in the cluster, and only replicates to these specific buddies. This greatly helps scalability as there is no longer a memory and network traffic impact every time another instance is added to a cluster.
One of the most common use cases of Buddy Replication is when a replicated cache is used by a servlet container to store HTTP session data. One of the pre-requisites to buddy replication working well and being a real benefit is the use of session affinity, also known as sticky sessions in HTTP session replication speak. What this means is that if certain data is frequently accessed, it is desirable that this is always accessed on one instance rather than in a round-robin fashion as this helps the cache cluster optimise how it chooses buddies, where it stores data, and minimises replication traffic.
If this is not possible, Buddy Replication may prove to be more of an overhead than a benefit.
Buddy Replication uses an instance of a org.jboss.cache.buddyreplication.BuddyLocator which contains the logic used to select buddies in a network. JBoss Cache currently ships with a single implementation, org.jboss.cache.buddyreplication.NextMemberBuddyLocator, which is used as a default if no implementation is provided. The NextMemberBuddyLocator selects the next member in the cluster, as the name suggests, and guarantees an even spread of buddies for each instance.
The NextMemberBuddyLocator takes in 2 parameters, both optional.
- numBuddies - specifies how many buddies each instance should pick to back its data onto. This defaults to 1.
- ignoreColocatedBuddies - means that each instance will try to select a buddy on a different physical host. If not able to do so though, it will fall back to colocated instances. This defaults to true.
Also known as replication groups, a buddy pool is an optional construct where each instance in a cluster may be configured with a buddy pool name. Think of this as an 'exclusive club membership' where when selecting buddies, BuddyLocators would try and select buddies sharing the same buddy pool name. This allows system administrators a degree of flexibility and control over how buddies are selected. For example, a sysadmin may put two instances on two separate physical servers that may be on two separate physical racks in the same buddy pool. So rather than picking an instance on a different host on the same rack, BuddyLocators would rather pick the instance in the same buddy pool, on a separate rack which may add a degree of redundancy.
In the unfortunate event of an instance crashing, it is assumed that the client connecting to the cache (directly or indirectly, via some other service such as HTTP session replication) is able to redirect the request to any other random cache instance in the cluster. This is where a concept of Data Gravitation comes in.
Data Gravitation is a concept where if a request is made on a cache in the cluster and the cache does not contain this information, it then asks other instances in the cluster for the data. If even this fails, it would (optionally) ask other instances to check in the backup data they store for other caches. This means that even if a cache containing your session dies, other instances will still be able to access this data by asking the cluster to search through their backups for this data.
Once located, this data is then transferred to the instance which requested it and is added to this instance's data tree. It is then (optionally) removed from all other instances (and backups) so that if session affinity is used, the affinity should now be to this new cache instance which has just taken ownership of this data.
Data Gravitation is implemented as an interceptor. The following (all optional) configuration properties pertain to data gravitation.
- dataGravitationRemoveOnFind - forces all remote caches that own the data or hold backups for the data to remove that data, thereby making the requesting cache the new data owner. If set to false an evict is broadcast instead of a remove, so any state persisted in cache loaders will remain. This is useful if you have a shared cache loader configured. Defaults to true.
- dataGravitationSearchBackupTrees - Asks remote instances to search through their backups as well as main data trees. Defaults to true. The resulting effect is that if this is true then backup nodes can respond to data gravitation requests in addition to data owners.
- autoDataGravitation - Whether data gravitation occurs for every cache miss. My default this is set to false to prevent unnecessary network calls. Most use cases will know when it may need to gravitate data and will pass in an Option to enable data gravitation on a per-invocation basis. If autoDataGravitation is true this Option is unnecessary.
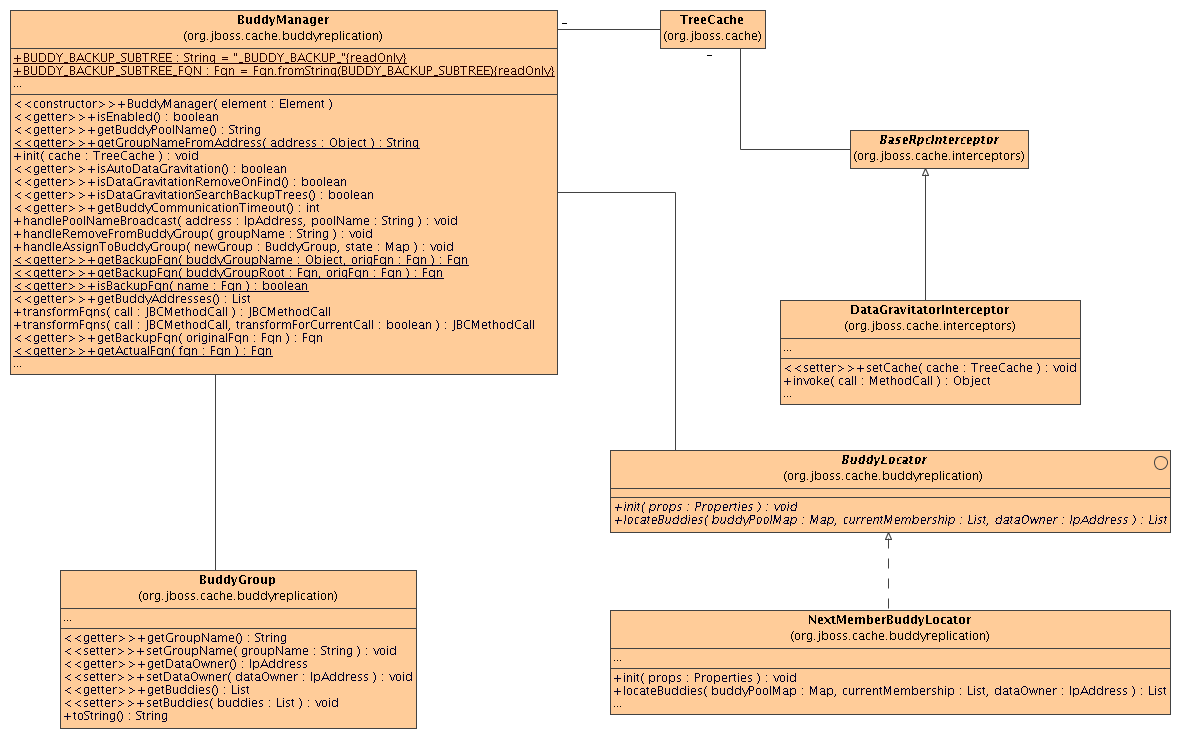
Figure 4.1. Class diagram of the classes involved in buddy replication and how they are related to each other
<!-- Buddy Replication config -->
<attribute name="BuddyReplicationConfig">
<config>
<!-- Enables buddy replication. This is the ONLY mandatory configuration element here. -->
<buddyReplicationEnabled>true</buddyReplicationEnabled>
<!-- These are the default values anyway -->
<buddyLocatorClass>org.jboss.cache.buddyreplication.NextMemberBuddyLocator</buddyLocatorClass>
<!-- numBuddies is the number of backup nodes each node maintains. ignoreColocatedBuddies means that
each node will *try* to select a buddy on a different physical host. If not able to do so though,
it will fall back to colocated nodes. -->
<buddyLocatorProperties>
numBuddies = 1
ignoreColocatedBuddies = true
</buddyLocatorProperties>
<!-- A way to specify a preferred replication group. If specified, we try and pick a buddy why shares
the same pool name (falling back to other buddies if not available). This allows the sysdmin to hint at
backup buddies are picked, so for example, nodes may be hinted topick buddies on a different physical rack
or power supply for added fault tolerance. -->
<buddyPoolName>myBuddyPoolReplicationGroup</buddyPoolName>
<!-- Communication timeout for inter-buddy group organisation messages (such as assigning to and removing
from groups, defaults to 1000. -->
<buddyCommunicationTimeout>2000</buddyCommunicationTimeout>
<!-- Whether data is removed from old owners when gravitated to a new owner. Defaults to true. -->
<dataGravitationRemoveOnFind>true</dataGravitationRemoveOnFind>
<!-- Whether backup nodes can respond to data gravitation requests, or only the data owner is supposed to respond.
defaults to true. -->
<dataGravitationSearchBackupTrees>true</dataGravitationSearchBackupTrees>
<!-- Whether all cache misses result in a data gravitation request. Defaults to false, requiring callers to
enable data gravitation on a per-invocation basis using the Options API. -->
<autoDataGravitation>false</autoDataGravitation>
</config>
</attribute>
If a cache is configured for invalidation rather than replication, every time data is changed in a cache other caches in the cluster receive a message informing them that their data is now stale and should be evicted from memory. Invalidation, when used with a shared cache loader (see chapter on Cache Loaders) would cause remote caches to refer to the shared cache loader to retrieve modified data. The benefit of this is twofold: network traffic is minimised as invalidation messages are very small compared to replicating updated data, and also that other caches in the cluster look up modified data in a lazy manner, only when needed.
Invalidation messages are sent after each modification (no transactions), or at the end of a transaction, upon successful commit. This is usually more efficient as invalidation messages can be optimised for the transaction as a whole rather than on a per-modification basis.
Invalidation too can be synchronous or asynchronous, and just as in the case of replication, synchronous invalidation blocks until all caches in the cluster receive invalidation messages and have evicted stale data while asynchronous invalidation works in a 'fire-and-forget' mode, where invalidation messages are broadcast but doesn't block and wait for responses.