Here's some sample code before we dive into the API itself:
TreeCache tree = new TreeCache();
tree.setClusterName("demo-cluster");
tree.setClusterProperties("default.xml"); // uses defaults if not provided
tree.setCacheMode(TreeCache.REPL_SYNC);
tree.createService(); // not necessary, but is same as MBean lifecycle
tree.startService(); // kick start tree cache
tree.put("/a/b/c", "name", "Ben");
tree.put("/a/b/c/d", "uid", new Integer(322649));
Integer tmp = (Integer) tree.get("/a/b/c/d", "uid");
tree.remove("/a/b");
tree.stopService();
tree.destroyService(); // not necessary, but is same as MBean lifecycle
The sample code first creates a TreeCache instance and then configures it. There is another constructor which accepts a number of configuration options. However, the TreeCache can be configured entirely from an XML file (shown later) and we don't recommend manual configuration as shown in the sample.
The cluster name, properties of the underlying JGroups stack, and cache mode (synchronous replication) are configured first (a list of configuration options is shown later). Then we start the TreeCache. If replication is enabled, this will make the TreeCache join the cluster, and acquire initial state from an existing node.
Then we add 2 items into the cache: the first element creates a node "a" with a child node "b" that has a child node "c". (TreeCache by default creates intermediary nodes that don't exist). The key "name" is then inserted into the "/a/b/c" node, with a value of "Ben".
The other element will create just the subnode "d" of "c" because "/a/b/c" already exists. It binds the integer 322649 under key "uid".
The resulting tree looks like this:
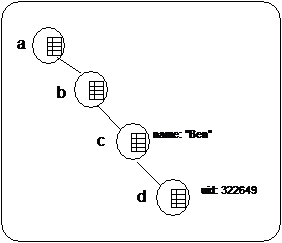
The TreeCache has 4 nodes "a", "b", "c" and "d". Nodes "/a/b/c" has values "name" associated with "Ben" in its map, and node "/a/b/c/d" has values "uid" and 322649.
Each node can be retrieved by its absolute name (e.g. "/a/b/c") or by navigating from parent to children (e.g. navigate from "a" to "b", then from "b" to "c").
The next method in the example gets the value associated with key="uid" in node "/a/b/c/d", which is the integer 322649.
The remove() method then removes node "/a/b" and all subnodes recursively from the cache. In this case, nodes "/a/b/c/d", "/a/b/c" and "/a/b" will be removed, leaving only "/a".
Finally, the TreeCache is stopped. This will cause it to leave the cluster, and every node in the cluster will be notified. Note that TreeCache can be stopped and started again. When it is stopped, all contents will be deleted. And when it is restarted, if it joins a cache group, the state will be replicated initially. So potentially you can recreate the contents.
In the sample, replication was enabled, which caused the 2 put() and the 1 remove() methods to replicated their changes to all nodes in the cluster. The get() method was executed on the local cache only.
Keys into the cache can be either strings separated by slashes ('/'), e.g. "/a/b/c", or they can be fully qualified names Fqns . An Fqn is essentially a list of Objects that need to implement hashCode() and equals(). All strings are actually transformed into Fqns internally. Fqns are more efficient than strings, for example:
String n1 = "/300/322649";
Fqn n2 = new Fqn(new Object{new Integer(300), new Integer(322649)});In this example, we want to access a node that has information for employee with id=322649 in department with id=300. The string version needs two map lookups on Strings, whereas the Fqn version needs two map lookups on Integers. In a large hashtable, the hashCode() method for String may have collisions, leading to actual string comparisons. Also, clients of the cache may already have identifiers for their objects in Object form, and don't want to transform between Object and Strings, preventing unnecessary copying.
Note that the modification methods are put() and remove(). The only get method is get().
There are 2 put() methods[2] : put(Fqn node, Object key, Object key) and put(Fqn node, Map values). The former takes the node name, creates it if it doesn't yet exist, and put the key and value into the node's map, returning the previous value. The latter takes a map of keys and values and adds them to the node's map, overwriting existing keys and values. Content that is not in the new map remains in the node's map.
There are 3 remove() methods: remove(Fqn node, Object key), remove(Fqn node) and removeData(Fqn node). The first removes the given key from the node. The second removes the entire node and all subnodes, and the third removes all elements from the given node's map.
The get methods are: get(Fqn node) and get(Fqn node, Object key). The former returns a Node[3] object, allowing for direct navigation, the latter returns the value for the given key for a node.
Also, the TreeCache has a number of getters and setters. Since the API may change at any time, we recommend the Javadoc for up-to-date information.