New SFSB Caching Implementation
Following is a discussion of a new EJB3 SFSB caching implementation that I (Brian Stansberry) have been working on. This is based on some prototype work Carlo de Wolf did last fall and some discussions between us over the months since then.
Primary goals are to:
Isolate the SFSB caching logic from the ejb3-core project.
Properly handle Extended Persistence Context sharing between beans in a nested hierarchy.
Create an SPI so the JBoss Cache-based distributed caching solution can be separated from the main caching module.
Comply with TCK.
The current state of this code can be found at https://svn.jboss.org/repos/jbossas/projects/ejb3/branches/cluster-dev. Non-committers can use http://anonsvn.jboss.org/repos/jbossas/projects/ejb3/branches/cluster-dev. The cluster-dev branch is an experimental development branch created for this work.
-
Project Structure and Dependencies
There are actually two relevant projects in the cluster-dev branch:
cache -- contains the main caching abstractions and the default implementation. This project's only allowed dependency on another ejb3 project is on ext-api.
cache-jbc2 -- contains an implementation of the cache project's SPI that works with JBoss Cache 2.x. This project's only allowed dependencies on other ejb3 projects are ext-api and cache. This project is actually quite small, with only 4 classes in src/main.
If desired, other peers to cache-jbc2 could be created (e.g. a cache-jbc14 that works with JBoss Cache 1.4.x). Like cache-jbc2 they would be implementations of the cache project's SPI and could only depend on ext-api and cache.
Other ejb3 projects (i.e. core) should only have a compile-time dependency on cache. No other project should depend on cache-jbc2 at compile time.
The cache project includes the following main packages:
org.jboss.ejb3.cache.api -- the "client" API for the caching system; i.e. the API code in core should use. Client projects like core can only import classes from this package; no imports from other packages are allowed.
org.jboss.ejb3.cache.spi -- SPI classes to support specific implementations like cache-jbc2. Classes in these packages should only import classes from org.jboss.ejb3.cache.api. Includes a subpackage org.jboss.ejb3.cache.spi.impl that contains non-required helper classes for SPI implementers (abstract superclasses and the like).
org.jboss.ejb3.cache.impl -- the default implementation of the API/SPI. No class outside of this package should import a class inside of it.
If desired, the cache project could itself be divided into 3 projects: cache-api, cache-spi and cache-impl. I didn't bother taking things that far.
-
Key Abstractions
The following class diagram shows the key abstractions in the caching system. Note the MockBeanContext and MockBeanContainer classes; those are mock implementations of StatefulBeanContext and StatefulBeanContainer respectively. Hereafter I'll refer to them as StatefulBeanContext and StatefulBeanContainer, since those are the classes that will play these roles in a real system.
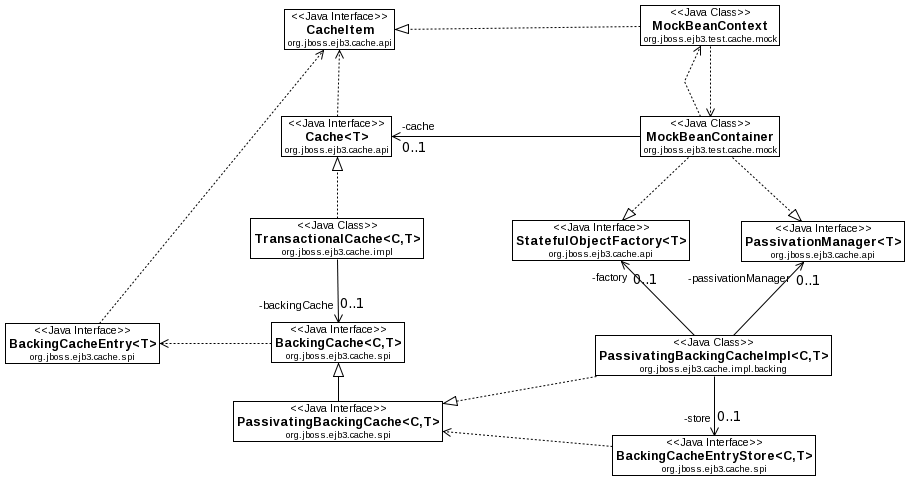
StatefulBeanContainer uses an implementation of Cache. The StatefulBeanContexts it creates implement the simple CacheItem interface. A Cache knows how to work with a CacheItem. A major goal of the design is to make the CacheItem interface as simple as possible; i.e. to not impose requirements on StatefulBeanContext. Another goal is to make the Cache interface as simple as possible; i.e. to neither impose requirements on StatefulBeanContainer nor to expose to code in core capabilities it can abuse.
The standard impl of the caching system is divided into two tiers:
The first is a "client facing" tier that implements the org.jboss.ejb3.cache.api.Cache interface. The standard implementation is org.jboss.ejb3.cache.impl.TransactionalCache. This class is an expansion on the LongevityCache concept Carlo de Wolf added to the trunk cache project. A "client facing" cache should take care of 2 key tasks:
Control client access to items (i.e. StatefulBeanContexts). Ensure only one caller thread or transaction at a time can access a given context.
Monitor the process of creating a new StatefulBeanContext to detect a situation where creating one context results in the creation of others in a nested bean hierarchy. If a nested bean hierarchy is detected, ensure that all contexts in the hierarchy becomes members of a commonly managed org.jboss.ejb3.cache.spi.SerializationGroup. More on serialization groups below.
The first tier cache is able to remain relatively simple by delegating to the second tier for most other tasks. A second tier cache implements the org.jboss.ejb3.cache.spi.BackingCache interface or one of its subinterfaces. It manages items of type org.jboss.ejb3.cache.spi.BackingCacheEntry<T extends CacheItem>. A BackingCacheEntry is an object that wraps a CacheItem (e.g. a StatefulBeanContext), exposing a richer interface to allow the BackingCache to track the state of the item with respect to client usage, execution of passivation/activation/replication callbacks, etc. The BackingCache is responsible for the following:
Actually creating the cached items. It does this by delegating to a provided StatefulObjectFactory. StatefulBeanContainer is the provided StatefulObjectFactory impl, so the bean container is the ultimate creator of the cached StatefulBeanContexts.
If the cache supports passivation and/or replication, ensuring appropriate callbacks (e.g. @PrePassivate) are invoked on the cache items. The actual invocation of the callbacks is delegated to a provided PassivationManager. Again, StatefulBeanContainer is the provided PassivationManager impl, so the bean container actually handles invoking the callbacks.
If replication is supported, actually replicating the cached items. This is delegated to a provided BackingCacheEntryStore. Whether and exactly how replication is done is an implementation detail of the BackingCacheEntryStore.
If passivation or expiration are configured, tracking when items are used and deciding what items need to be passivated or expired. Actually storing passivated items in a persistent store. These activities are also delegated to a provided BackingCacheEntryStore. Exactly how the details are handled is an implementation detail of the BackingCacheEntryStore.
-
SerializationGroup Management
As noted above, a SerializationGroup is formed when a set of nested bean contexts are created as part of the creation of a parent bean, the simplest example being during creation of an instance of bean type A which has an @EJB field of bean type B. The SerializationGroup is used to ensure that:
All members of the group are always serialized (for passivation or replication) as a single unit. This ensures that any shared references to any Extended Persistence Context or managed entities are still shared references after deserialization.
All members of the group have needed passivation/replication callbacks invoked before any serialization.
Serialization groups are only relevant when the cache supports passivation or replication.
It is not possible for a Cache impl to know in advance whether a particular bean type will result in nested bean hierarchies, and thus create the need for a serialization group. Some instances of a particular bean type may be part of a group, and others may not; which is the case cannot be determined until the bean instances are created. The StatefulBeanContainer for A might be able to detect that A has a ref to B, but the container for B has no way to know A is using it. So, a Cache impl that supports passivation or replication must support serialization groups, but should also efficiently handle beans that are not part of a group. The following class diagram shows the structure that allows this:
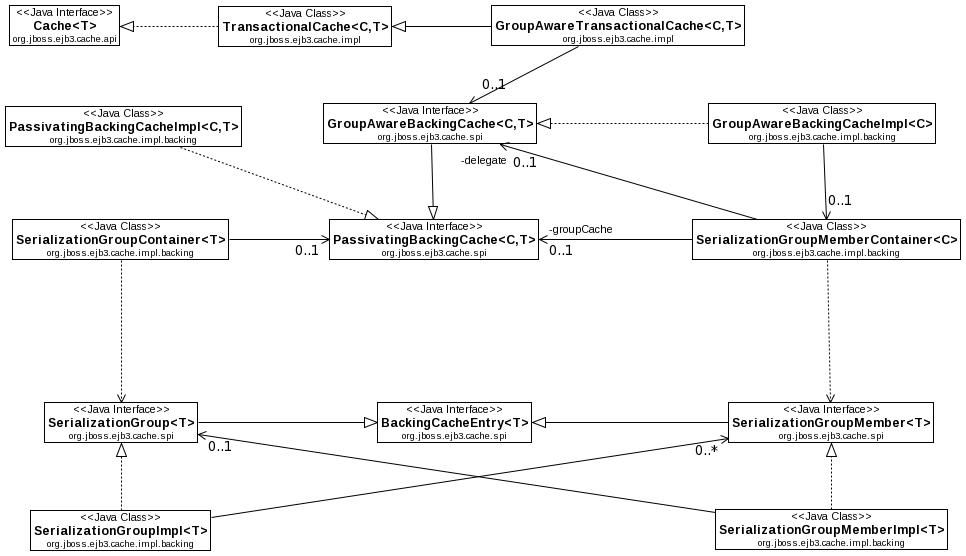
TODO: Discussion of the above diagram.
-
XPCs and the Shared State Map
A primary goal of this effort is to isolate the caching logic from the ejb3 core project. In line with this, a StatefulBeanContext only needs to implement the simple CacheItem interface. A StatefulBeanContext should have no need to have references to other members of its SerializationGroup.
A roadblock on the path to achieving this goal involved the injection and closing of Extended Persistence Contexts. See the Branch_4_2 StatefulBeanContext.getExtendedPersistenceContext(String id) and StatefulBeanContext.closeExtendedPCs() methods to see how managing the lifecycle of XPCs forced the bean context class to have references to the other members of its group. A better solution needed to be found. Furthermore, any solution could not involve the cache code having any understanding of the internals of StatefulBeanContext.
The solution in cluster-dev is to ensure that a shared reference to a Map<Object, Object> is provided to each bean context as part of its creation. The GroupAwareTransactionalCacheImpl instantiates a Map<Object, Object> as the first step of creating a bean context, and makes it available to the cache used by any nested beans via a ThreadLocal. This map is passed to the StatefulBeanContainer via the StatefulObjectFactory.create(Class<?> initTypes{FOOTNOTE DEF }, Object initValues{FOOTNOTE DEF }, Map<Object, Object> sharedState) method. The StatefulBeanContainer injects it into the newly created StatefulBeanContext. Result is all bean contexts in a group have a shared reference to a map.
The StatefulBeanContext can then make use of the map to track information about shared XPCs. See the org.jboss.ejb3.test.cache.mock.MockBeanContext class in the cache project testsuite to see a prototype of how to use this map manage XPC lifecycles across a group.
-
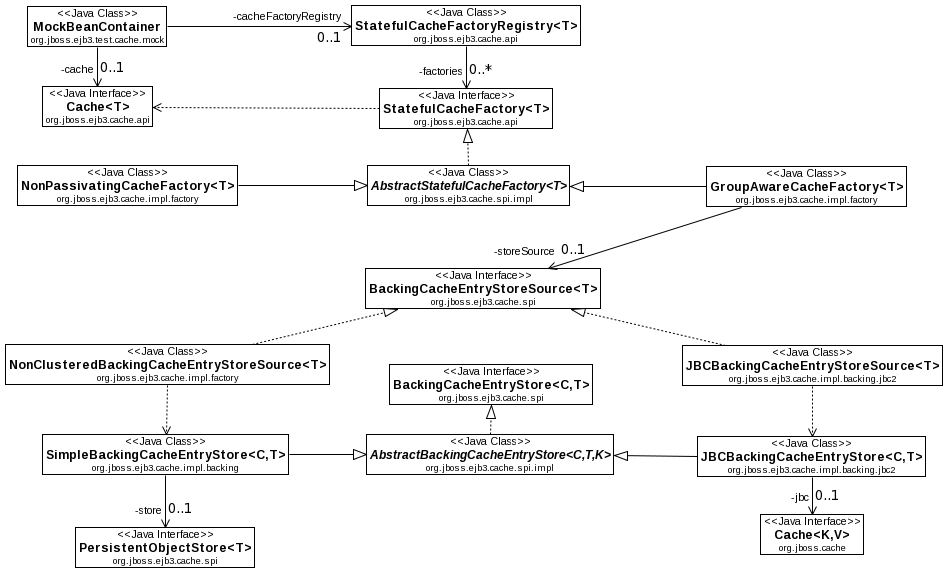
Cache Factories
TODO: Add description, sample beans.xml
-
Passivation and Expiration
One of the responsibilities of the caching system is to determine when items need to be passivated or expired (removed due to inactivity). This work needs to be done by a background thread (or threads).
The cluster-dev work implements this by adding a simple PassivationProcessor interface, the heart of which is a single public void processPassivationExpiration() method that gets invoked by the background thread. An appropriate implementer of PassivationProcessor is a class that has detailed knowledge of when items were last used and of what items are in memory or passivated. In practice, this proved to be the implementations of BackingCacheEntryStore, or, in the non-passivating case, NonPassivatingBackingCacheImpl (which needs to manage expiration even though it ignores passivation.)
As for managing the background thread(s), two different approaches are supported:
Dedicated Thread Approach
In this approach, each processor has its own java.util.Timer thread, and creates a java.util.TimerTask subclass PassivationExpirationRunner which invokes the processor's processPassivationExpiration() method.

Thread Pool Approach
The obvious downside to the "Dedicated Thread Approach" is the possibility of having a large number of background threads if there are a large number of deployed beans. The "Thread Pool Approach" avoids this problem by using a central coordinator object with a thread pool:
The PassivationExpirationCoordinatorImpl is injected into each StatefulCacheFactory. As part of the cache creation process, the cache factory registers the PassivationProcessors it creates with the coordinator.
The PassivationExpirationCoordinatorImpl itself has a java.util.Timer thread, and itself is a java.util.TimerTask subclass. When it's run() executes, it checks if it has an injected ThreadPool. If yes, it uses a configurable number of threads from the pool to invoke processPassivationExpiration() on the registered PassivationProcessors. If there is no thread pool, the coordinator uses its own time thread to invoke processPassivationExpiration() on the processors.
-
Major Unresolved Issues
1) The biggest unresolved issue has to do with ordering of transaction Synchronization execution. The standard Cache impl TransactionalCache uses a Synchronization to help ensure only a single transaction can concurrently access a given bean and that the bean isn't passivated while the transaction is still active. The synchronization's beforeCompletion() callback is used to notify the cache that the bean is now free. When the synchronization notifies the cache the transaction is completed, the first tier TransactionalCache releases the bean to the BackingCache, which may then trigger replication (if clustered).
This can lead to problems if the bean implements javax.ejb.SessionSynchronization. EJB3 also implements SessionSynchronization support using a transaction Synchronization. This synchronization needs to execute before the synchronization registered by TransactionalCache. Otherwise any state changes made by the bean during the SessionSynchronization.beforeCompletion() callback may not get replicated.
Test org.jboss.ebj3.test.cache.distributed.SessionSynchronizationInterceptorUnitTestCase shows this problem.
Ordering execution of synchronizations is a bit of a pain, since the javax.transaction API doesn't include any direct support for it. In this case, the problem is harder, because the default ordering provided by most transaction managers, execute in order of registration, will not work. The TransactionalCache synchronization will get registered first (when the bean is created), but the SessionSynchronization synchronization needs to execute first.
The solution I've seen to this problem elsewhere (Hibernate, JBC) is to have an ordering synchronization somehow made available to all code that needs to coordinate. The ordering synchronization is the one that gets registered with the transaction. The other synchronizations register with it, using an API it exposes to support the desired ordering. When the ordering synchronization gets a callback, it cycles through its register synchronizations, invoking the callback on them.
This is simple enough to implement; the problem here is how to expose such an ordering synchronization to code in both cache and core.
STATUS: Carlo pointed out javax.transaction.TransactionSynchronizationRegistry, which I'd thought was an EE 6 thing. It's not, and solves the problem nicely. Only drawback is the need to use JNDI.
2) The current architecture can't support the SerializedConcurrentAccess usage of the current StatefulInstanceInterceptor. Basically, TransactionalCache has no logic to block calls if a bean is in use by another thread. This is per a discussion between Carlo and myself. I don't think it would be much work to add such logic; we'd just need to add a public boolean isSerializedConcurrentAccess() method to CacheItem so the cache could know whether to block.
STATUS: The above will work for the current usage, where concurrent access to a bean is not allowed, and the SerializedConcurrentAccess just controls whether an attempt at concurrent access blocks or fails immediately. But need to think a bit about new stuff EJB 3.1 adds in this area, try to get things set up correctly for that. Addition of @Read and @ReadWrite annotations on methods somewhat implies the concurrent-access control on a bean depends on what methods have been invoked. I need to read the draft spec.
-
TODOs
Resolve the transaction synchronization ordering issue above.
Look more closely into remove handling; make sure it's right.
Expose managment info via Cache interface.
A lot more unit testing.
Port the other ejb3 projects into cluster-dev. Convert the core code to work with the new cache concepts.
TCK runs using the cluster-dev code.
Port cluster-dev to ejb3 trunk.
-
Testsuite
The testsuite in the cache and cache-jbc2 projects make extensive use of mock objects that are meant to mock the behavior of an EJB3 system, particularly the relevant behavior of StatefulBeanContainer and StatefulBeanContext. These mocks should be expanded/enhanced as necessary to support testing as much as possible of a real EJB3 system's usage of an SFSB cache.
The Maven install goal for cache installs a 'jboss-ejb3-cache-tests.jar' that contains the classes in the project's src/test folder. This allows cache-jbc2 to reuse the cache project mock objects in its own testsuite. Thanks to Andrew Rubinger for pointing out how to get this to work with maven. See the pom.xml files from each project to see how this is done.
The cache project's testsuite includes a org.jboss.ejb3.test.cache.distributed package, which includes a pretty good mock impl of a JBoss Cache-based BackingCacheEntryStore. Things added to cache that are intended to support a distributed cache setup should be tested here; don't just test them in cache-jbc2.









Comments