Next Generation Web Tier Load Balancing Design
Design document for the next generation JBoss AS web tier load balancing architecture.
See here for the discussion forum related to this document.
See also the following wiki pages:
Implementation details:
Mod-Cluster_Management_Protocol
JBossWeb listener:
Mod_cluster project home page:
Future directions:
JBC data partitioning and mod_cluster
Initial document is derived from discussions held in Neuchatel on December 6, 2007. Participants were Bela Ban, Frederic-Clere, Jason Greene, Sacha Labourey, Mircea Markus, Remy Maucherat, Brian Stansberry, Manik Surtani, Mladen Turk, Jimmy Wilson and Galder Zamarreno.
Key Design Goals
Dynamic registration of AS instances and context mountings; no need to statically configure the JBossWeb "workers" or context mountings on the Apache httpd side.
Cluster-wide load balance calculations maintained on the AS side, with appropriate load factors sent to the httpd side as circumstances change.
Pluggable policies for calculating the load balance factors.
AS instances send lifecycle notifications to the httpd side, equivalent to the "disable('D')" and "stop ('S')" values available with mod_proxy Parameter definition (See http://httpd.apache.org/docs/2.2/mod/mod_proxy.html#proxypass).
More fine grained; individual contexts can be disabled/stopped, not just entire server instances.
Basic Architecture
A new Apache module, "mod_cluster" will be created, based on the existing mod_proxy module. See JBNATIVE-53 for details.
Normal web request traffic will be sent from mod_cluster to the JBossWeb instances' AJP connector using the AJP protocol. No changes to the AJP protocol are necessary.
On the AS side, a new ModClusterService will be created. It will send cluster configuration and load balance weighting information to the httpd side via HTTP/HTTPS.
The ModClusterService will be made aware of how to contact the httpd side via static configuration; there will be no dynamic discovery of httpd instances. (The list of httpd instances could, however, be changed at runtime via a management tool.)
Modes
We discussed two possible modes in which the ModClusterService could operate:
"Non-Clustered" AS instances
Here the AS instances do not exchange information amongst themselves. Think in terms of a group of AS instances running the "default" config, with no JGroups channel open.
In this mode, each AS instance directly communicates with each server on the Apache httpd side. The ModClusterService would be able to send messages to the httpd side regarding:
Registration and configuration information.
Mounting information
Lifecycle events (disable/stop the instance or one of its contexts)
However, any load balance factor sent from the AS instances would be a static configuration value, equivalent to the
worker.xxx.lbfactor
in a mod_jk
workers.properties
file.
Minor "nice-to-have" is the ability for the load balance factor to be updated at runtime (e.g. via a management tool) with the new value passed to the httpd side.
A related "nice-to-have" is the ability for a node to update it's load balance factor itself. For example, if the node feels it is overloaded, it can reduce it's factor. If all nodes did that simultaneously, it would have no effect, which is OK.
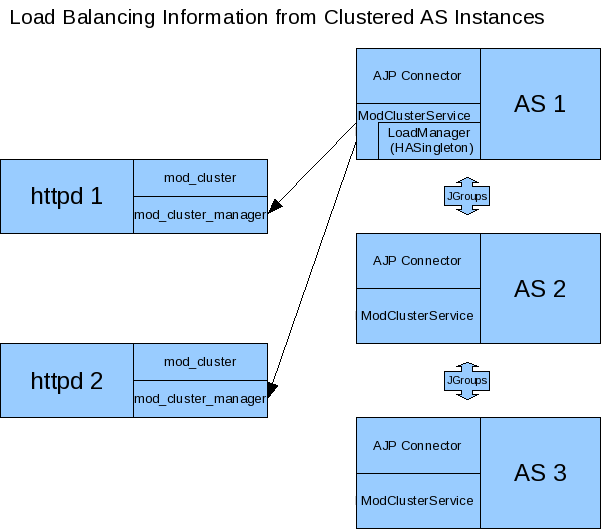
Question: In this mode, can mod_cluster still make load balance decisions a la the mod_jk Request, Session and Traffic methods? Or would the load balance factor from the static configuration be the sole factor in the load balance decision?
Answer: The load balance factor would be the sole factor in the decision; don't want to maintain load balance policy code in mod_cluster. See above "nice-to-have" on allowing each node to dynamically update its load balance factor to reflect its own appraisal of its status.
"Clustered" AS instances
The AS instances would form a cluster (using JGroups) and could thus exchange various metrics that would be used in the load balance factor calculation. ModClusterService would include an HASingleton component such that one member of the cluster would be responsible for collating these metrics, deriving the load balance factor for all group members, and sending that consolidated information to each server on the Apache httpd side.
Question: In this mode, would messages other than load balance factors be transmitted via the HASingleon member? My (BES) initial take on this is it seems simpler to restrict the HASingleton messages to load balance information.
Answer: That is probably enough. But it could interesting to see if a node of the cluster could "ping" htttpd.
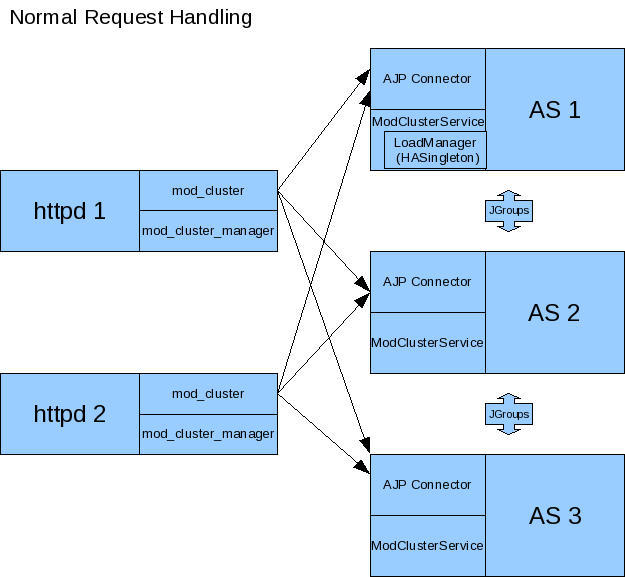
Normal Request Handling
Normal request traffic is passed from mod_cluster to the AJP connector in the normal, fashion; i.e. via AJP over a pool of long-lasting connections.
AS to mod_cluster Communications -- Mod-Cluster Management Protocol (MCMP)
The specification of the communication protocol between the ModClusterService and httpd is the main detail area that needs to be hammered out between the AS clustering team and the mod_cluster side. Once that is done each side can proceed fairly independently.
Communication from ModClusterService to httpd will be done via HTTP or HTTPS. There is ongoing discussion of what HTTP method is most appropriate. GET can be fairly human-readable and is easiest to use via a CLI (e.g. telnet). But, GET requests are limited by the 8 Kbytes4 bytes URL length limitation, and even it is unlikely that some requests would need to go beyond that length, POST seems like a reasonable choice and there is currently discussion of using a WebDAV-like approach where we define custom request types (corresponding to the message types below). It is not easy to pass parameter values as HTTP headers rather because httpd logic will optimize them (app: /myapp
is transform while parsing into app: /myapp, /hisapp).
This communication would be over the regular port that httpd is listening on, with the request being internally handled by mod_cluster_manager based on a special context path mount in httpd.conf. Basically, something like
SetHandler mod-cluster
. What port to use depends on how httpd is configured.
Issue: Securing this mount is a bit trickier than the jkstatus case, which could often just be set to only "Allow from: 127.0.0.1". Such a simple approach won't work here as a large number of AS instances will need to be able to communicate.
Solution:It is possible to have the SetHandler directive in a VirtualHost where SSL is mandatory.
Example of Secure SetHandler:
Listen 9443 <VirtualHost _default_:9443> SSLEngine on SSLCipherSuite ALL:!ADH:!EXPORT56:RC4+RSA:+HIGH:+MEDIUM:+LOW:+SSLv2:+EXP:+eNULL SSLCertificateFile conf/server.crt SSLCertificateKeyFile conf/server.key SSLCACertificateFile conf/server-ca.crt SSLVerifyClient require SSLVerifyDepth 10 SetHandler mod-cluster </VirtualHost>
Basic categories of messages:
Configuration Information
Per node. Initially provided by each node (or perhaps by the HASingleton) during the startup process for the node.
The "Connection Directives" and "Advanced Worker Directives" sections of the Apache Tomcat Connector - Reference Guide give a good description of the various options supported by mod_jk.
Question/TODO: Which if any of these are not available, given that the code base is mod_proxy not mod_jk?
Answer: See http://community.jboss.org/wiki/Mod-Clusternodeconf for a proposal for that stuff.
Other configuration items mentioned in the Neuchatel discussions that are not directly mentioned in the reference guide:
Authentication information (not sure what was meant here)
Max sessions
Question: My assumption is we'll support updating these values after the initial registration of a worker.
Answer: Those value will be stored in shared memory and should be used while processing new connections and new requests
Load Balancing Factors
Either a single load balance factor (in "non-clustered" mode) or a set of factors (in "clustered" mode).
General Load Balancing Configurations
Things like the mod_jk 'sticky-session' and 'sticky-session-force' directives. See the "Load Balancing Directives section in the Apache Tomcat Connector - Reference Guide for others.
Issue: If the ModClusterService is operating in "non-clustered" mode, it isn't clear who configures these.
Answer: In "non-clustered" mode, each AS instance will independently send this information, with any new data overriding the older. It is the responsibility of the user to ensure that each AS instance has the same configuration for these global values.
Management Message Types
Requests from ModClusterService notify the httpd side of lifecycle events: startup/shutdown of JBossWeb instances; deploy/undeploy of webapps.
Requests are sent via HTTP/HTTPS (80, 443); the exact HTTP request method is a subject of ongoing discussion.
CONFIG: Send configuration information for a node or set of nodes.
ENABLE-APP: Send requests and assign new sessions to the specified app. Use of to identify the app means enable all apps on the given node.
DISABLE-APP: apache should not create new session for this webapp, but still continue serving existing session on this node. Use of to identify the app means disable all apps on the given node.
STOP-APP: New requests for this webapp should not be sent to this node. Use of to identify the app means stop all apps on the given node.
REMOVE-APP: No requests for this webapp should be sent to this node. Use of to identify the app means the node has been removed from the cluster. In this case all other configuration information for the node will be removed and any open connection between httpd and the node will be closed.
STATUS: Send the current load balance factor for this node (or a set of nodes). Periodically sent. mod_cluster_manager responds with a STATUS-RSP. Interesting suggestion is to support sending a different load balance factor per webapp.
INFO: Request configuration info from mod_cluster_manager. Response would include information on what virtual hosts are configured (so per-webapp commands can specify the correct virtual host) and other info that ModClusterService can make available to management tools (e.g. what addresses/ports httpd is listening on.) mod_cluster_manager responds with a INFO-RSP message.
DUMP: Request a text dump of the current configuration seen by mod_cluster_manager. mod_cluster_manager responds with a DUMP-RSPcontaining a raw ascii text corresponding to the current configuration.
- PING: Request check the availability of a httpd or a cluster nodes from httpd (using the node name (JVMRoute or Scheme, Host and Port). mod_cluster_manager will respond with a PING-RSP which have a similar format to STATUS-RSP. (Since version 0.0.1 of the protocol).
Previous iteration also had ENABLE/DISABLE/STOP commands that applied to all apps on a node. This usage can be handled by passing '' as the webapp name. A STOP message may still be useful as a signal to mod_cluster_manager to completely remove all configuration information for a node from memory. Perhaps a different name than STOP, e.g. REMOVE.
A detailed protocol proposal could be found in Mod-Cluster_Management_Protocol.
Responses to the above requests will contain something like:
"HTTP/1.1 200 OK" When command has been processed correctly.
"HTTP/1.1 500 VERSION 1.2.3" if something about the request was not understood. Version number helping the ModClusterService understand how to tailor future requests.
"HTTP/1.1 200 OK" and the response for the request (for STATUS and DUMP requests at least).
It could interesting to have the following for some requests:
List any any exclusion nodes (nodes that mod_cluster regards as failed due to problems responding to requests)
Metrics (open connections, number of retries, etc) that ModClusterService may wish to use in load balancing calculations.
Virtual Hosts
Messages pertaining to particular webapps will need to qualify the webapp's context name with virtual host information. This virtual host information needs to be in terms httpd can understand rather than in the terms JBossWeb uses. E.g. if httpd has a virtual host labs.jboss.org and JBossWeb has a server.xml host element named "labs", the communication to mod_cluster_manager must qualify the relevant webapps with "labs.jboss.org".
The purpose of the INFO message is to acquire the necessary information to understand the virtual hosts on the httpd side. ModClusterService will need to analyze the names and aliases of the Host instances running in JBossWeb and correlate them to the appropriate httpd virtual hosts.
ModClusterService Design
The ModClusterService will be based on a modular architecture, with as many points as possible pluggable and extendable. Major components include:
A pluggable adapter for interfacing with the mod_cluster_manager. The details of the interaction (POST vs GET vs WebDAV like commands, even whether mod_cluster_manager is the load balancer) should be completely abstracted away from the rest of the service.
Group communication module for coordinating gathering of metrics, managing the HASingleton, etc.
Metrics gathering module, for gathering needed metrics from the local node. Likely will include pluggable submodules for interfacing with various AS subsystems (e.g. JBossWeb for web tier usage statistics, transaction subsystem, general core server metrics like CPU and memory usage, etc.)
Load balancing manager for coordination of metrics gathering.
Load balance policy which calculates the current load balance factors.
Configuration module for determining information about the runtime environment, e.g. what port the AJP connector is listening on, what Tomcat Host instances are running, etc. Perhaps this module will read a configuration file for other ModClusterService-specific static information, although my general preference would be to configure that sort of thing via -beans.xml property injection.
Management module for exposing an interface to external management tools
Clustering Issues
Domains
We want full support for domains.
A domain is a way to group nodes that share sessions.
However, there are a couple different ways users might implement these; we need to think through how to handle both. In both cases a JGroups channel is used for session replication, with group membership limited to the members of the domain. The question is how the JGroups channel used for intra-cluster ModClusterService traffic is set up:
The channel includes all members. In this case, there is one HASingleton which manages things for all domains.
There is a channel per domain, in which case there are multiple HASingleton instances, one per domain.
The former seems pretty simple, and can generate more accurate load balancing factors, but the latter is probably preferable for users to configure. To support the latter, we need to ensure the message protocol doesn't result in messages from one domain accidentally affecting another domain. For example:
An HASingleton sends a CONFIG message with data for a set of nodes. mod_cluster_manager should not treat the absence of a particular node from the message as meaning that node should be dropped from memory. Rather, once a node is configured it should require a specific message to remove it.
Same thing for load balance factors. If a message is received that says A has factor 2, that remains A's factor until specifically changed. A STATUS message changing B, C and D's factor with no mention of A doesn't somehow set A to 0.
Split-Brain Syndrome
Problem here is if there is a network partition disrupting intra-cluster JGroups traffic. Assume traffic between the httpd boxes and the AS instances is unaffected. This will result in a situation where more than one HASingleton will be running, with each feeling the nodes in the other subcluster have died. We need to avoid a situation where each HASingleton tells mod_cluster_manager to stop sending traffic to the other subcluster's nodes, with the effect that no nodes are available.
Perhaps the way to deal with this is by having the HASingleton send a STATUS or some other message to mod_cluster_manager before handling what it sees as a node failure. If mod_cluster_manager regards the node as still being healthy, the singleton can regard this as a sign of a split-brain condition and defer telling mod_cluster_manager to remove the node.
Use cases
1. JBoss AS is started
Send CONFIG message to httpd, httpd adds information to internal tables, but does not yet connect to JBoss via AJP
CONFIG contains
Contents of workers.properties: IP address and port of JBoss
uriworkermap.properties
Changes to JBoss config are also sent via CONFIG, overwrites the existing entry at httpd
apache does not yet connect
Send ENABLE-APP (with list of all deployed webapps) to httpd
This would happen at the end of the startup phase, after the JBossWeb connectors are started. Need an internal notification to know when the connectors are started.
2. Webapp is deployed on a started JBoss AS
Send ENABLE-APP to apache
Apache adds webapp to its table and forwards requests to one of the JBoss instances which host this webapp
Tables need to maintain information about webapps like stopped, started, enabled, disabled etc
If we support different load balance factors per webapp, a CONFIG message with the initial factor would need to be sent before the ENABLE-APP
3. Webapp is undeployed
(Possibly) send DISABLE-APP to apache, apache disables the app in its tables
Requests with existing sessions are still sent to the node
Maybe wait until all sessions are drained
More sophisticated things can be done as well, such as waiting until no requests have come in within a configurable or dynamically determined period of time (e.g. 15 secs). Idea is to allow the webapp to be stopped on the node as soon as it is reasonable to assume any previous requests' session state has been replicated.
Send STOP-APP to apache
Apache removes webapp from its tables
4. JBoss is stopped (gracefully)
(Possibly) send DISABLE-APP with a '' parameter to apache, apache disables all apps for the node in its tables
Requests with existing sessions are still sent to the node
Maybe wait until all sessions are drained
More sophisticated things can be done as well, such as waiting until no requests have come in within a configurable or dynamically determined period of time (e.g. 15 secs). Idea is to allow the webapp to be stopped on the node as soon as it is reasonable to assume any previous requests' session state has been replicated.
Send STOP-APP with a '' parameter to apache, apache stops all apps for the node in its tables
Issue: The above causes mod_cluster to stop routing requests to the node, but it still maintains all configuration information for the node in memory. Perhaps an additional STOP or REMOVE command is needed to signal mod_cluster to remove all configuration information.
5. JBoss sends load (STATUS) information to apache
Sent regularly, in configurable intervals.
Either single or clustered: multiple or one value, e.g. for multiple: A:1, B:4, C:2, D:4. Same as load balance type 'R' currently
Response is used to get info from httpd,
workers mod_cluster sees as being in error state
If ModClusterService doesn't believe a listed worker has failed, it can send messages to mod_cluster telling it to try to recover the worker (see below).
any httpd-side metrics being tracked by the AS for management or load balancing purposes
If in non-clustered mode and we don't send dynamic load information, we can also simply not send this message
Issue: If we don't send a STATUS message and mod_cluster regards a node as being in error state, the node will never know that and will never try to recover itself. As a solution 1) we could have each node periodically send a STATUS to avoid this, or 2) perhaps mod_cluster could do what mod_jk does, and run a background thread that tries to resurrect nodes in error state.
6. JBoss crashes
Two possible mechanisms for detecting the problem:
If clustered, the HA Singleton may detect the crashed node via the JGroups failure detection protocols.
Whether the JBoss AS nodes are clustered or not, mod_cluster may detect the failed node before JGroups does (e.g. via CPING/CPONG). mod_cluster marks the worker as being in error state.
In clustered mode, in the response to its next STATUS request the HA Singleton will be made aware of the fact that mod_cluster sees the node as failed
If ModClusterService still doesn't see the node as failed (i.e. JGroups FD/VERIFY_SUSPECT timeouts have not elapsed), it will send another CONFIG and set the node status to UP to mod_cluster_manager
mod_cluster will attempt to use the node again, and will fail
process repeats until JGroups detects the node failure
No matter which of the above paths is followed, once ModClusterService regards the node as failed it sends STOP-APP with a '' parameter to apache, apache stops all apps for the node in its tables
As in 4 above, we need a mechanism for telling apache to remove the worker config from memory
When the JBoss instance comes back up, it'll go through use case 1: a CONFIG message is sent which adds the nodes configuration, then ENABLE-APP to signal that requests can be sent.
7. JBoss instance hangs
Very similar to 5 above, only difference is it is possible the node will recover before JGroups removes it from the group.
Either way, when instance has rejoined the cluster, we will need to send another CONFIG to apache, so apache adds the JBoss instance to its tables
8. Connectivity is lost between mod_cluster and a node (non-clustered case)
This is conceptually similar to 7 above. mod_cluster cannot successfully connect to an AS instance, so it adds it to its error table.
If we decide that the non-clustered nodes will periodically send STATUS messages, the node will learn it is in the error list and try to recover itself (new CONFIG + ENABLE-APP)
Otherwise, a background process on the httpd side will need to periodically try to recover the node
9. Connectivity is lost between mod_cluster and a node (clustered case, node is not HASingleton)
Similar to 8 above. Here the HASingleton will for sure periodically send STATUS messages and will send a new CONFIG + ENABLE-APP to try to recover the node.
Remark: Without an asynchronous ping/pong this will cause QoS problems: The node will be marked UP and mod_cluster will forward new requests to it if the connectivity between mod_cluster and the node is still lost all those requests will timeout on connect and fall back to another node. See http://community.jboss.org/wiki/Mod-Clusterpingpong
10. Connectivity is lost between mod_cluster and a node (node is the HASingleton)
Tricky situation, as the singleton is basically non-functional if it cannot talk to the httpd side. This will need to be handled with an extension to the normal HASingleton handling whereby a master can force an election of a new singleton master if it detects it cannot contact httpd, with the election policy ensuring the problem node is not elected.
This perhaps can be done by storing a Boolean in the DRM for each node (rather than the usual meaningless String). The boolean indicates whether the node can send to mod_cluster_manager; election policy excludes nodes with 'false'. Node updates the DRM with a boolean 'false' when it detects a problem; this update should trigger a new election.
Perhaps we need a PING message that each node can use to check its ability to send to mod_cluster_manager?
Misc
All requests to apache are sent to the apache default port (80), or whichever port is configured
There's a dummy app (like 'status') which processes those requests (provided by mod-cluster-manager)
The AJP configuration can be completely set with a CONFIG message from the JBoss side
Anything that can be configured via the existing mod_jk 'status' webapp can be configured via MCMP
Other Considerations
It would be nice the an implementation of the ModClusterService could be deployed in AS 4.x.
Any code that interacts with JBossWeb to gather metrics would need to be pluggable to support any interface differences.
JGroups or HAPartition usage could be different, as could HASingleton usage.
So, a "nice-to-have".
Where should the code live. Who will use it (see issue above), what will the dependencies be, etc.



Comments