JBoss Cache consists of two components, Core Cache, and POJO Cache. Core Cache provides efficient memory storage, transactions, replication, eviction, persistent storage, and many other "core" features you would expect from a distributed cache. The Core Cache API is tree based. Data is arranged on the tree using nodes that each offer a map of attributes. This map-like API is intuitive and easy to use for caching data, but just like the Java Collection API, it operates only off of simple and serializable types. Therefore, it has the following constraints:
- If replication or persistence is needed, the object will then need to
implement the
Serializableinterface. E.g.,public Class Foo implements Serializable
- If the object is mutable, any field change will require a successive put operation on the cache:
value = new Foo(); cache.put(fqn, key, value); value.update(); // update value cache.put(fqn, key, value); // Need to repeat this step again to ask cache to persist or replicate the changes
- Java serialization always writes the entire object, even if only one field was changed. Therefore, large objects
can have significant overhead, especially if they are updated frequently:
thousand = new ThousandFieldObject(); cache.put(fqn, key, thousand); thousand.setField1("blah"); // Only one field was modified cache.put(fqn, key, thousand); // Replicates 1000 fields - The object structure can not have a graph relationship. That is, the object can not have
references to objects that are shared (multiple
referenced) or to itself (cyclic). Otherwise, the relationship will be broken upon
serialization (e.g., when replicate each parent object separately). For example, Figure 1
illustrates this problem during replication.
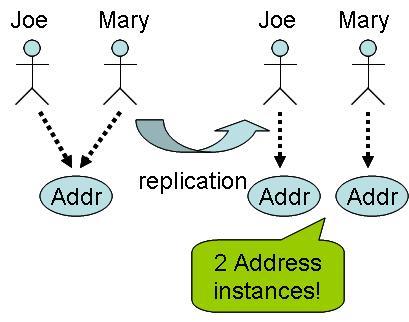
If we have two
Personinstances that share the sameAddress, upon replication, it will be split into two separateAddressinstances (instead of just one). The following is the code snippet using Cache that illustrates this problem:joe = new Person("joe"); mary = new Person("mary"); addr = new Address("Taipei"); joe.setAddress(addr); mary.setAddress(addr); cache.put("/joe", "person", joe); cache.put("/mary", "person", mary);
POJO Cache attempts to address these issues by building a layer on top of Core Cache which transparently maps normal Java object model operations to individual Node operations on the cache. This offers the following improvements:
- Objects do not need to implement
Serializableinterface. Instead they are instrumented, allowing POJO Cache to intercept individual operations. - Replication is fine-grained. Only modified fields are replicated, and they can be optionally batched in a transaction.
- Object identity is preserved, so graphs and cyclical references are allowed.
- Once attached to the cache, all subsequent object operationis will trigger a cache operation (like replication)
automatically:
POJO pojo = new POJO(); pojoCache.attach("id", pojo); pojo.setName("some pojo"); // This will trigger replication automatically.
In POJO Cache, these are the typical development and programming steps:
- Annotate your object with
@Replicable - Use
attach()to put your POJO under cache management. - Operate on the object directly. The cache will then manage the replication or persistence automatically and transparently.
More details on these steps will be given in later chapters.
Since POJO Cache is a layer on-top of Core Cache, all features available in Core Cache are also available in POJO Cache. Furthermore, you can obtain an instance to the underlying Core Cache by calling PojoCache.getCache(). This is useful for resusing the same cache instance to store custom data, along with the POJO model.