The federated repository source provides a unified repository consisting of information that is dynamically federated from multiple other
RepositorySource instances. This is a very powerful repository source that appears to be a single repository, when in
fact the content is stored and managed in multiple other systems. Each FederatedRepositorySource is typically configured
with the name of another RepositorySource that should be used as the local, unified cache of the federated content.
The FederatedRepositorySource then looks in the configuration repository to determine the various workspaces
and how other sources are projected into each workspace.
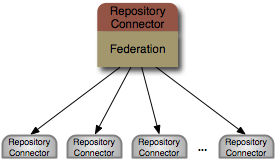
Each federated repository source provides a unified repository consisting of information that is dynamically federated from multiple other RepositorySource instances. The connector is configured with a number of projections that each describe where in the unified repository the federated connector should place the content from another source. Projections consist of the name of the source containing the content and a number of rules that define the path mappings, where each rule is defined as a string with this format:
pathInFederatedRepository => pathInSourceRepository
Here, the pathInFederatedRepository is the string representation of the path in the unified
(or federated) repository, and pathInSourceRepository is the string representation of the path of the
actual content in the underlying source. For example:
/ => /
is a trivial rule that states that all of the content in the underlying source should be mapped into the unified
repository such that the locations are the same. Therefore, a node at /a/b/c in the source would
appear in the unified repository at /a/b/c. This is called a mirror projection,
since the unified repository mirrors the underlying source repository.
Another example is an offset projection, which is similar to the mirror projection except that the federated path includes an offset not found in the source:
/alpha/beta => /
Here, a node at /a/b/c in the source would actually appear in the unified repository at
/alpha/beta/a/b/c. The offset path (/alpha/beta in this example) can have 1 or more segments.
(If there are no segments, then it reduces to a mirror projection.)
Often a rule will map a path in one source into another path in the unified source:
/alpha/beta => /foo/bar
Here, the content at /foo/bar is projected in the unified repository under /alpha/beta,
meaning that the /foo/bar prefix never even appears in the unified repository. So the node at
/foo/bar/baz/raz would appear in the unified repository at /alpha/beta/baz/raz. Again,
the size of the two paths in the rule don't matter.
Federated repositories that use a single projection are useful, but they aren't as interesting or powerful as those that use multiple projections. Consider a federated repository that is defined by two projections:
/ => / for source "S1" /alpha => /foo/bar for source "S2"
And consider that S1 contains the following structure:
+- a | +- i | +- j +- b +- k +- m +- n
and S2 contains the following:
+- foo
+- bar
| +- baz
| | +- taz
| | +- zaz
| +- raz
+- bum
+- bot
The unified repository would then have this structure:
+- a
| +- i
| +- j
+- b
| +- k
| +- m
| +- n
+- alpha
+- baz
+- taz
| +- zaz
+- raz
Note how the /foo/bum branch does not even appear in the unified repository, since it is outside of the
branch being projected. Also, the /alpha node doesn't exist in S1 or S2; it's what is called a
placeholder node that exists purely so that the nodes below it have a place to exist.
Placeholders are somewhat special: they allow any structure below them (including other placeholder nodes or real
projected nodes), but they cannot be modified.
Even more interesting are cases that involve more projections. Consider a federated repository that contains information about different kinds of automobiles, aircraft, and spacecraft, except that the information about each kind of vehicle exists in a different source (and possibly a different kind of source, such as a database, or file, or web service).
First, the sources. The "Cars" source contains the following structure:
+- Cars
+- Hybrid
| +- Toyota Prius
| +- Toyota Highlander
| +- Nissan Altima
+- Sports
| +- Aston Martin DB9
| +- Infinity G37
+- Luxury
| +- Cadillac DTS
| +- Bentley Continental
| +- Lexus IS350
+- Utility
+- Land Rover LR2
+- Land Rover LR3
+- Hummer H3
+- Ford F-150
The "Aircraft" source contains the following structure:
+- Aviation
+- Business
| +- Gulfstream V
| +- Learjet 45
+- Commercial
| +- Boeing 777
| +- Boeing 767
| +- Boeing 787
| +- Boeing 757
| +- Airbus A380
| +- Airbus A340
| +- Airbus A310
| +- Embraer RJ-175
+- Vintage
| +- Fokker Trimotor
| +- P-38 Lightning
| +- A6M Zero
| +- Bf 109
| +- Wright Flyer
+- Homebuilt
+- Long-EZ
+- Cirrus VK-30
+- Van's RV-4
Finally, our "Spacecraft" source contains the following structure:
+- Space Vehicles
+- Manned
| +- Space Shuttle
| +- Soyuz
| +- Skylab
| +- ISS
+- Unmanned
| +- Sputnik
| +- Explorer
| +- Vanguard
| +- Pioneer
| +- Marsnik
| +- Mariner
| +- Mars Pathfinder
| +- Mars Observer
| +- Mars Polar Lander
+- Launch Vehicles
| +- Saturn V
| +- Aries
| +- Delta
| +- Delta II
| +- Orion
+- X-Prize
+- SpaceShipOne
+- WildFire
+- Spirit of Liberty
So, we can define our unified "Vehicles" source with the following projections:
/Vehicles => / for source "Cars" /Vehicles/Aircraft => /Aviation for source "Aircraft" /Vehicles/Spacecraft => /Space Vehicles for source "Cars"
The result is a unified repository with the following structure:
+- Vehicles
+- Cars
| +- Hybrid
| | +- Toyota Prius
| | +- Toyota Highlander
| | +- Nissan Altima
| +- Sports
| | +- Aston Martin DB9
| | +- Infinity G37
| +- Luxury
| | +- Cadillac DTS
| | +- Bentley Continental
| +- Lexus IS350
| +- Utility
| +- Land Rover LR2
| +- Land Rover LR3
| +- Hummer H3
| +- Ford F-150
+- Aircraft
| +- Business
| | +- Gulfstream V
| | +- Learjet 45
| +- Commercial
| | +- Boeing 777
| | +- Boeing 767
| | +- Boeing 787
| | +- Boeing 757
| | +- Airbus A380
| | +- Airbus A340
| | +- Airbus A310
| | +- Embraer RJ-175
| +- Vintage
| | +- Fokker Trimotor
| | +- P-38 Lightning
| | +- A6M Zero
| | +- Bf 109
| | +- Wright Flyer
| +- Homebuilt
| +- Long-EZ
| +- Cirrus VK-30
| +- Van's RV-4
+- Spacecraft
+- Manned
| +- Space Shuttle
| +- Soyuz
| +- Skylab
| +- ISS
+- Unmanned
| +- Sputnik
| +- Explorer
| +- Vanguard
| +- Pioneer
| +- Marsnik
| +- Mariner
| +- Mars Pathfinder
| +- Mars Observer
| +- Mars Polar Lander
+- Launch Vehicles
| +- Saturn V
| +- Aries
| +- Delta
| +- Delta II
| +- Orion
+- X-Prize
+- SpaceShipOne
+- WildFire
+- Spirit of Liberty
Other combinations are of course possible.
This connctor executes against the federated repository by projecting them into requests against the underlying sources that are being federated.
One important design of the connector framework is that requests can be submitted in a batch, which may be processed more efficiently than if each request was submitted one at a time. This connector design accomplishes this by projecting the incoming requests into requests against each source, then submitting the batch of projected requests to each source, and then transforming the results of the projected requests back into original requests.
This is accomplished using a three-step process:
Process the incoming requests and for each generate the appropriate request(s) against the sources (dictated by the workspace's projections). These "projected requests" are then enqueued for each source.
Submit each batch of projected requests to the appropriate source, in parallel where possible. Note that the requests are still ordered correctly for each source.
Accumulate the results for the incoming requests by post-processing the projected requests and transforming the source-specific results back into the federated workspace (again, using the workspace's projections).
This process is a form of the fork-join divide-and-conquer algorithm, which involves splitting a problem into smaller
parts, forking new subtasks to execute each smaller part, joining on the subtasks (waiting until all have finished), and then
composing the results. Technically, Step 2 performs the fork and join operations, but this class uses RequestProcessor
implementations to do Step 1 and 3 (called ForkRequestProcessor and JoinRequestProcessor, respectively).
Such fork-join style techniques are well-suited to parallel processing. This connector uses an ExecutorService to allow these different processors to operate concurrently. This can greatly improve the performance as perceived by the clients, since indeed much of the operations on the different sources are occurring at the same time.
It is also possible that not every incoming Request get projected to all sources. Indeed, many operations can
effectively be mapped to a single projection. In such cases, the overhead of the federated
connector is quite minimal.
Note
Requests that include the Path within the request's Location can be very quickly mapped to the correct projection,
and thus such federated requests can be processed with very little overhead. However, when requests contain Locations
that only contain identification properties (e.g., UUIDs), the connector may not be able to determine the correct
projection(s), and may have to simply forward the request to all of the projections. This is obviously less desirable,
so when possible ensure that the Request objects include the Path.
The federated connector behavior for read-only requests is fairly obvious. In the best case, the connector determines the appropriate projections, forwards the request into the appropriate sources, and then combines the results. But what happens with change requests?
Currently, the federated connector requires that each ChangeRequest be mapped to one and only one projection.
However, when a single projection cannot be determined for a ChangeRequest, the connector throws an error.
This is thought to be a minimal problem that will not actually be an issue in most uses of the federated connector. If you find that your usage does indeed fall into this category, please let us know via the mailing lists or log an enhancement request in JIRA. Be sure to include as much detail as possible about the scenario, the problem condition, and the desired behavior.
The federated repository uses other RepositorySources that are to be federated and a RepositorySource that is to be used as the cache of the unified contents. These are configured in another RepositorySource that is treated as a configuration repository, which should contain information about the workspaces and how other sources are projected:
<!-- Define the federation configuration. -->
<dna:workspaces>
<dna:workspace jcr:name="default">
<!-- Define how the content in the two sources maps to the federated/unified repository.
This example puts the 'Cars' and 'Aircraft' content underneath '/vehicles', but the
'Configuration' content (which is defined by this file) will appear under '/'. -->
<dna:projections>
<!-- Project the 'Cars' content, starting with the '/Cars' node. -->
<dna:projection jcr:name="Cars projection" dna:source="Cars" dna:workspaceName="workspace1">
<dna:projectionRules>/Vehicles/Cars => /Cars</dna:projectionRules>
</dna:projection>
<!-- Project the 'Aicraft' content, starting with the '/Aircraft' node. -->
<dna:projection jcr:name="Aircarft projection" dna:source="Aircraft" dna:workspaceName="workspace2">
<dna:projectionRules>/Vehicles/Aircraft => /Aircraft</dna:projectionRules>
</dna:projection>
<!-- Project the 'System' content. Only needed when this source is accessed through JCR. -->
<dna:projection jcr:name="System projection" dna:source="System" dna:workspaceName="default">
<dna:projectionRules>/jcr:system => /</dna:projectionRules>
</dna:projection>
</dna:projections>
</dna:workspace>
</dna:workspaces>
Note
We're using XML to represent a graph structure, since the two map pretty well. Each XML element represents
a node and XML attributes represent properties on a node. The name of the node is defined by either the
jcr:name attribute (if it exists) or the name of the XML element. And we use XML namespaces
to define the namespaces used in the node and property names. BTW, this is exactly how the XML graph importer
works.
While the majority of the configuration is defined using the configuration source (as discussed above), the FederatedRepositorySource
class have have a few JavaBean properties:
Table 13.1. FederatedRepositorySource properties
| Property | Description |
|---|---|
| name | The name of the repository source, which is used by the RepositoryService when obtaining a RepositoryConnection by name. |
| retryLimit | Optional property that, if used, defines the number of times that any single operation on a RepositoryConnection to this source should be retried following a communication failure. The default value is '0'. |