This chapter provides instructions for downloading and running a sample application that demonstrates how JBoss DNA works with a JCR repository to automatically sequence changing content to extract useful information. So read on to get the simple application running, and then in the next chapter we'll dive into the source code for the example and show how to use JBoss DNA in your own applications.
JBoss DNA uses Maven 2 for its build system, as is this example. Using Maven 2 has several advantages, including the ability to manage dependencies. If a library is needed, Maven automatically finds and downloads that library, plus everything that library needs. This means that it's very easy to build the examples - or even create a maven project that depends on the JBoss DNA JARs.
Note
To use Maven with JBoss DNA, you'll need to have JDK 5 or 6 and Maven 2.0.9 (or higher).
Maven can be downloaded from http://maven.apache.org/, and is installed by unzipping the
maven-2.0.9-bin.zip file to a convenient location on your local disk. Simply add $MAVEN_HOME/bin
to your path and add the following profile to your ~/.m2/settings.xml file:
<settings>
<profiles>
<profile>
<id>jboss.repository</id>
<activation>
<property>
<name>!jboss.repository.off</name>
</property>
</activation>
<repositories>
<repository>
<id>snapshots.jboss.org</id>
<url>http://snapshots.jboss.org/maven2</url>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
<repository>
<id>repository.jboss.org</id>
<url>http://repository.jboss.org/maven2</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>repository.jboss.org</id>
<url>http://repository.jboss.org/maven2</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</pluginRepository>
<pluginRepository>
<id>snapshots.jboss.org</id>
<url>http://snapshots.jboss.org/maven2</url>
<snapshots>
<enabled>true</enabled>
</snapshots>
</pluginRepository>
</pluginRepositories>
</profile>
</profiles>
</settings>
This profile informs Maven of the two JBoss repositories (snapshots and releases) that contain all of the JARs for JBoss DNA and all dependent libraries.
The next step is to download the example for this Getting Started guide, and extract the contents to a convenient location on your local disk. You'll find the example contains the following files, which are organized according to the standard Maven directory structure:
examples/pom.xml
sequencers/pom.xml
/src/main/assembly
/config
/java
/resources
/test/java
/resources
repository/pom.xml
/src/main/assembly
/config
/java
/resources
/test/java
/resources
There are essentially three Maven projects: a sequencers project, a repository project,
and a parent project. All of the source for the sequencing example is located in the sequencers subdirectory,
while all of the source for the repository example is located in the repository subdirectory.
And you may have noticed that none of the JBoss DNA libraries are there. This is where Maven comes in.
The two pom.xml files tell Maven everything it needs to know about what libraries are required and
how to build the example.
In a terminal, go to the examples directory and run:
$ mvn install
This command downloads all of the JARs necessary to compile and build the example, including the JBoss DNA libraries, the libraries they depend on, and any missing Maven components. (These are downloaded from the JBoss repositories only once and saved on your machine. This means that the next time you run Maven, all the libraries will already be available locally, and the build will run much faster.) The command then continues by compiling the example's source code (and unit tests) and running the unit tests. The build is successful if you see the following:
$ mvn install ... [INFO] ------------------------------------------------------------------------ [INFO] Reactor Summary: [INFO] ------------------------------------------------------------------------ [INFO] Getting Started examples .............................. SUCCESS [2.106s] [INFO] Sequencer Examples .................................... SUCCESS [9.768s] [INFO] ------------------------------------------------------------------------ [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESSFUL [INFO] ------------------------------------------------------------------------ [INFO] Total time: 12 seconds [INFO] Finished at: Wed May 07 12:00:06 CDT 2008 [INFO] Final Memory: 14M/28M [INFO] ------------------------------------------------------------------------ $
If there are errors, check whether you have the correct version of Maven installed and that you've correctly updated your Maven settings as described above.
If you've successfully built the examples, there will be a new examples/sequencers/target/ directory that contains
all of the generated output for the sequencers example, including a dna-example-sequencers-basic.dir/ subdirectory
that contains the following:
run.shis the *nix shell script that will run the sequencer example application.log4j.propertiesis the Log4J configuration file.jackrabbitConfig.xmlis the Jackrabbit configuration file, which is set up to use a transient in-memory repository.jackrabbitNodeTypes.cnddefines the additional JCR node types used by this example.sample1.mp3is a sample MP3 audio file you'll use later to upload into the repository.caution.gif,caution.png, andcaution.jpgare images that you'll use later and upload into the repository.project1subdirectory contains some Java source that can be loaded into the repository.libsubdirectory contains the JARs for all of the JBoss DNA artifacts as well as those for other libraries required by JBoss DNA and the sequencer example.
Note
JBoss DNA and the sequencer example uses Apache Jackrabbit version 1.4.5. This version is stable and used by a number of other projects and applications. However, you should be able to use any version of Jackrabbit, as long as that version uses the same JCR API.
Just remember, if the version of Jackrabbit you want to use for these examples is not in the Maven repository, you'll have to either add it or add it locally. For more information, see the Maven documentation.
Similarly, the examples/repository/target/ directory contains all of the generated output for the repository example, including
a dna-example-repository-basic.dir/ subdirectory that contains the following:
run.shis the *nix shell script that will run the repository example application.log4j.propertiesis the Log4J configuration file.aircraft.xmlis an XML file containing the information that the example application imports into its "Aircraft" repository.cars.xmlis an XML file containing the information that the example application imports into its "Cars" repository.configRepository.xmlis an XML file containing the information that the example application imports into its "Configuration" repository and which defines how the application sets up access to the other example repositories.libsubdirectory contains the JARs for all of the JBoss DNA artifacts as well as those for other libraries required by JBoss DNA and the repository example.
The sequencing example consists of a client application that sets up an in-memory JCR repository and that allows a user to upload files into that repository. The client also sets up the DNA services with two sequencers so that if any of the uploaded files are PNG, JPEG, GIF, BMP or other images, DNA will automatically extract the image's metadata (e.g., image format, physical size, pixel density, etc.) and store that in the repository. Alternatively, if the uploaded file is an MP3 audio file, DNA will extract some of the ID3 metadata (e.g., the author, title, album, year and comment) and store that in the repository.
To run the client application, go to the examples/sequencers/target/dna-example-sequencers-basic.dir/
directory and type ./run.sh. You should see the command-line client and its menus in your terminal:
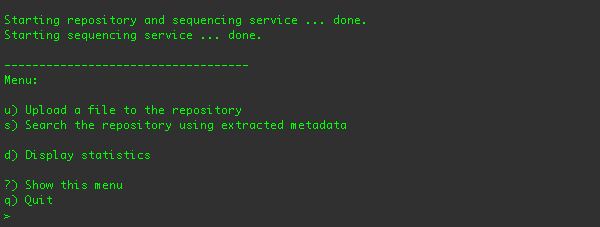
From this menu, you can upload a file into the repository, search for media in the repository, print sequencing statistics,
or quit the application.
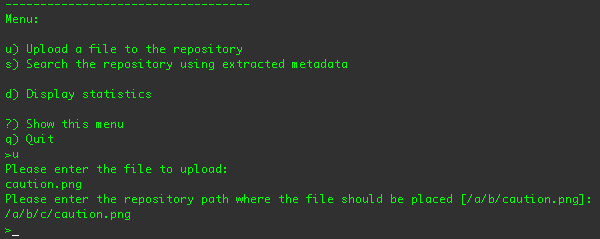
The first step is to upload one of the example images. If you type 'u' and press return, you'll be prompted to supply the
path to the file you want to upload. Since the application is running from within the
examples/sequencers/target/dna-example-sequencers-basic.dir/ directory, you can specify any of the files
in that directory without specifying the path:
You can specify any fully-qualified or relative path. The application will notify you if it cannot find the file you
specified. The example client configures JBoss DNA to sequence MP3 audio files, Java source files, or image files with one of
the following extensions (technically, nodes that have names ending in the following):
jpg, jpeg, gif, bmp, pcx, png,
iff, ras, pbm, pgm, ppm, and psd.
Files with other extensions in the repository path will be ignored. For your convenience, the example provides several
files that will be sequenced (caution.png, caution.jpg, caution.gif, and
sample1.mp3) and one image that will not be sequenced (caution.pict). Feel free to try other files.
After you have specified the file you want to upload, the example application asks you where in the repository you'd like to
place the file. (If you want to use the suggested location, just press return.) The client application
uses the JCR API to upload the file to that location in the repository, creating any nodes (of type nt:folder)
for any directories that don't exist, and creating a node (of type nt:file) for the file. And, per the JCR specification,
the application creates a jcr:content node (of type nt:resource) under the file node.
The file contents are placed on this jcr:content node in the jcr:data property. For example, if you specify
/a/b/caution.png, the following structure will be created in the repository:
/a (nt:folder)
/b (nt:folder)
/caution.png (nt:file)
/jcr:content (nt:resource)
@jcr:data = {contents of the file}
@jcr:mimeType = {mime type of the file}
@jcr:lastModified = {now}
Other kinds of files are treated in a similar way.
When the client uploads the file using the JCR API, DNA gets notified of the changes, consults the sequencers to see whether
any of them are interested in the new or updated content, and if so runs those sequencers. The image sequencer processes image
files for metadata, and any metadata found is stored under the /images branch of the repository. The MP3 sequencer
processes MP3 audio files for metadata, and any metadata found is stored under the /mp3s
branch of the repository. And metadata about Java classes are stored under the /java area of the repository.
All of this happens asynchronously, so any DNA activity doesn't impede or slow down the client activities.
So, after the file is uploaded, you can search the repository for the image metadata using the "s" menu option:
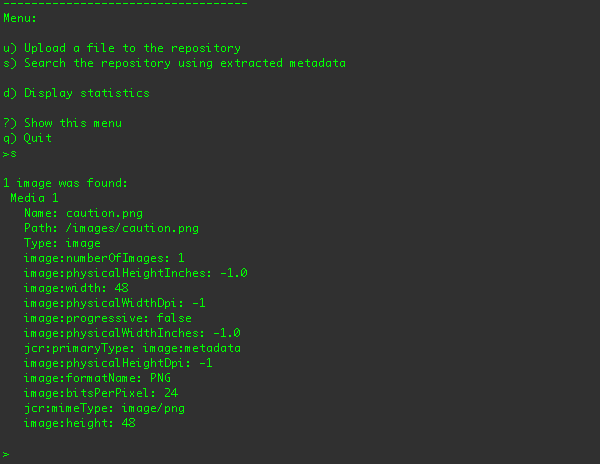
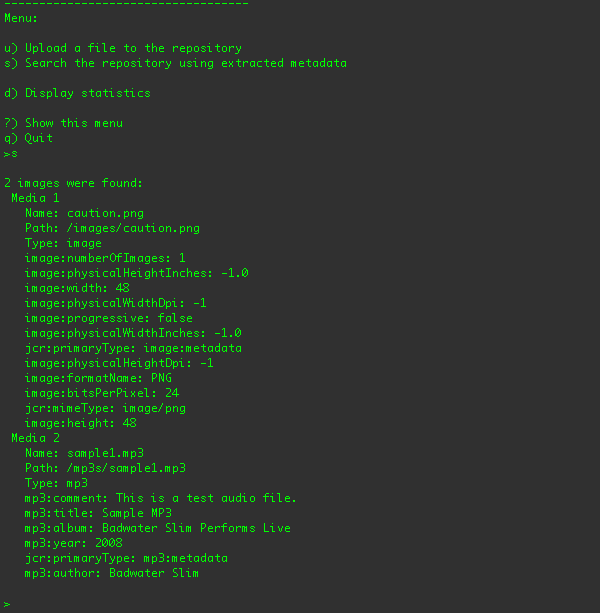
Here are the search results after the sample1.mp3 audio file has been uploaded (to the /a/b/sample1.mp3 location):
You can also display the sequencing statistics using the "d" menu option:
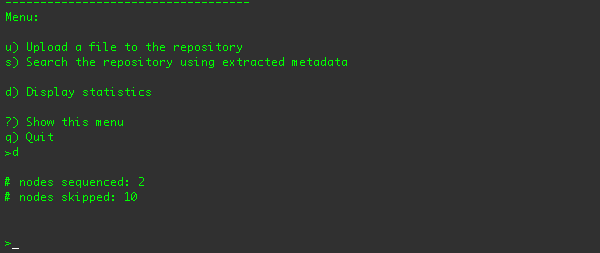
These stats show how many nodes were sequenced, and how many nodes were skipped because they didn't apply to the sequencer's
criteria.
Note
There will probably be more nodes skipped than sequenced, since there are more nt:folder and nt:resource
nodes than there are nt:file nodes with acceptable names.
You can repeat this process with other files. Any file that isn't an image or MP3 files (as recognized by the sequencing configurations that we'll describe later) will not be sequenced.
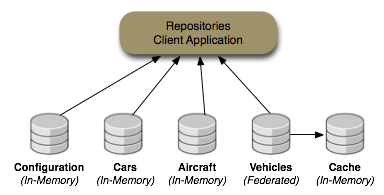
The repository example consists of a client application that sets up three DNA repositories (named "Cars", "Airplanes", and "Configuration") as well as a federated repository ("Vehicles") that dynamically federates the information from the three other repositories and a cache repository (named "Cache") in which the federated content is stored. The client application allows you to interactively navigate each of these repositories just as you would navigate the directory structure on a file system.
This collection of repositories is shown in the following figure:
Most of the repositories are in-memory repositories (using the In-Memory repository connector), but the federated "Vehicles" repository
content is federated from the other repositories and cached into the "Cache" repository. This is shown in the following figure:
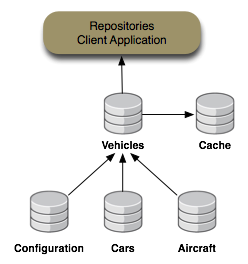
Figure 3.7. Vehicles repository content is federated from the Cars, Airplanes and Configuration repositories
To run the client application, go to the examples/repository/target/dna-example-repositories-basic.dir/
directory and type ./run.sh. You should see the command-line client and its menus in your terminal:
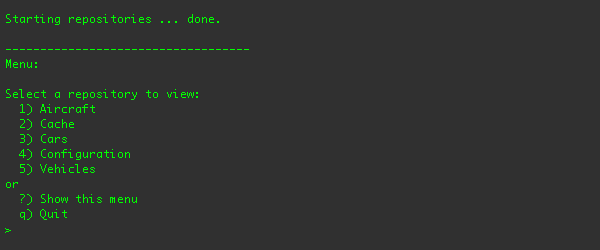
From this menu, you can see the list of repositories, select one, and navigate through that repository in a manner similar
to a *nix command-line shell (although the client itself uses the JCR API to interact with the repositories).
Here are some of the commands you can use:
Table 3.1. Repository client commands to navigate a repository
| Command | Description |
|---|---|
| pwd | Print the path of the current node (e.g., the "working directory") |
| ls [path] | List the children and properties of the node at the supplied path, where "path" can be any relative path or absolute path. If "path" is not supplied, the current working node's path is used. |
| cd path | Change to the specified node, where "path"
can be any relative path or absolute path. For example, "cd alpha" changes the current node to be a child named
"alpha"; "cd .." changes the current node to the parent node; "cd /a/b" changes
the current node to be the "/a/b" node. |
| exit | Exit this repository and return the list of repositories. |
If you were to select the "Cars" repository and use some of the commands, you should see something similar to:
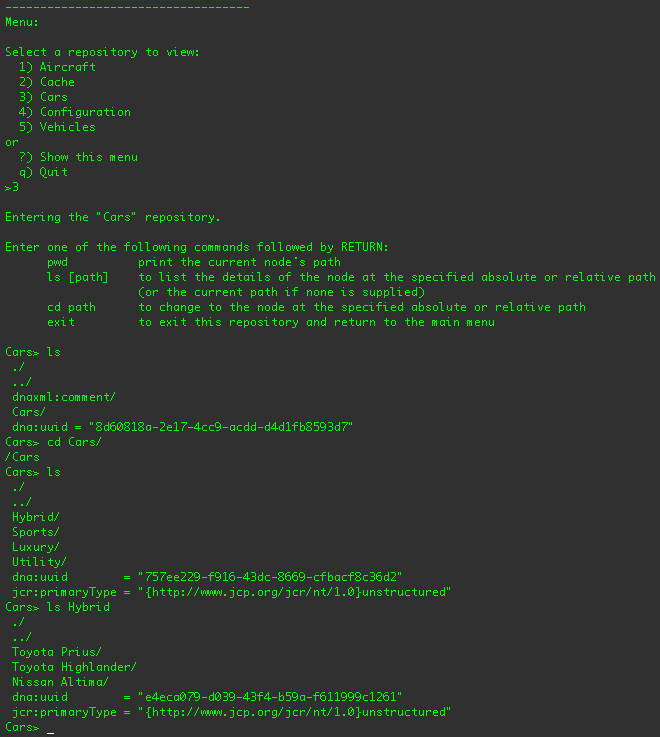
You can also choose to navigate the "Vehicles" repository, which projects the "Cars" repository content under the
/Vehicles/Cars node, the "Airplanes" content under the /Vehicles/Airplanes branch,
and the "Configuration" content under /dna:system.
Try using the client to walk the different repositories. And while this is a contrived application, it does demonstrate the use of JBoss DNA to federate repositories and provide access through JCR.
In this chapter you downloaded, installed, and built the two example applicationss. With the sequencer client, you could upload files into a JCR repository, while JBoss DNA automatically sequenced the image, MP3, or Java source files you uploaded, extracted the metadata from the files, and stored that metadata inside the repository. The repository client allowed you to walk through multiple repositories, including one whose content was federated from multiple other repositories.
These example applications were very simplistic. In fact, running through the examples probably only took you a few minutes. So while these applications won't win any awards, they hopefully showed you the basics of what JBoss DNA can do.
In the next two chapters, we'll venture into the code to get an understanding of how JBoss DNA actually works. The next chapter reviews the sequencer application and talks about how you can use DNA sequencers in your own applications. Then in the following chapter we'll venture into the repositories example code to show how you can use DNA repositories, including federated repositories, in your own applications.