JBossAS-clustering
This document describes requirements to support clustering of JBossAS 4 servers. The core foundation for clustering is JBossCache / JGroups.
This was not always the case, so we need to decide which versions of JBossAS we support. I think 4.x + EAP 4 would be good. I would not go and support 3.x. As there seem to be differences in 4.x and EAP, we probably need to narrow this even further.
Use cases will apply to AS 5 too, but at least some implementation details will change.
Definition of cluster
To make things easier, we will define a cluster as a set of JBossAS nodes, that all have the same jboss.partition.name .
1 Use cases
This section lists basic use case that JBossON should be able to handle. In addition, the system must be able to change system wide cluster properties -- see below in section 4
I got one textual use case description:
"As a EAP/JON Customer I need to be able to provision/deprovision clustered EAP instances using the JON tool. I should be able to do this from a certified "Golden Config" the corporation has stored in JON Server. The "Golden Config" was previously grabbed from a correctly setup node in a cluster. As I am provisioning this node I am able to config what cluster it is in and what apps are to run on it. The JON Server also has a nice screen to see the clusgters and what is running on them."
Once the cluster is up an running I am able to deploy new versions of the application to the cluster using the JON Server content repository. Ideally the EAP 5.x instances can do this side by side. ie. Version 1 runs next to Version 1.1 in the same EAP instance. JON Server notifies mod_jk/mod_cluster and a little load moves to Version 1.1. If all goes well we starve off all Version 1.0 clients and move them to Version 1.1. If Version 1.1 does not work out, then we put the load back on Version 1.0 and call it even."
1.1 Configure frontend mod_jk (and mod_cluster)
Users often have an Apache httpd as a load balancer in front of a JBossAS / Tomcat cluster. We should be able to configure apache when we see that mod_jk is already present on the apache. We don't need to try to install mod_jk on our own.
This configuring must be coordinated with enabling UseJK on Tomcat for the cluster nodes involved. See also below
Parts of this are:
- Setting session affinity ("sticky sessions") in mod_jk
- Setting the weight per node in mod_jk (and perhaps even have an operation to modify it when the backend AS gets loaded too much)
- Allow a node to drown to be able to do maintenance on it or even completely take it out of service - this means, changing the LB configuration so that no more new requests are sent to it.
- Configure number of threads for AJP connector -- with respect to the number of worker threads in httpd+mod_jk
It is important to support mod_jk, as there is a huge customer base out there running it.
1.1.1 Support of mod_cluster
There is a new (upcoming) replacement for it, mod_cluster (http://jboss.org/mod_cluster or ModClusterDesign ) that we also should support in a later stage. One goodie of mod_cluster is that the AS instances can by themselves send their load balancing info. Also configuring the list of workers is mostly done on the AS side and not on the httpd side, which is less work for us to support (one could even argue, that the user should configure mod_cluster on his own and then only use this information to configure the AS side).
1.2 Change topology
A cluster consists of multiple nodes. The topology is usually not static, but can grow and shrink depending on the load of the cluster.
We will not support of copying libraries in server/.../lib to the new nodes or even removing them from nodes that are to be removed.
We need to support clusters with and without domains
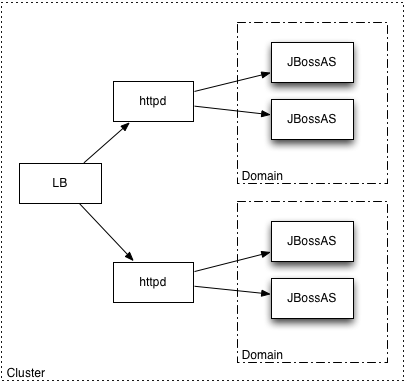
1.2.1 Add node to cluster
Adding a node to a cluster can consist of three parts
1) selection of an AS to add to the cluster

The user first selects one or more AS to add, then one cluster to add the nodes to. Then he clicks 'Assign' to trigger the next step.
2) select the buddy replication group this new AS instance should be part of.
3) modifying the properties of a node to match the properties of the already existing nodes
4) booting a JBossAS into a different configuration (after this target configuration has been adjusted). This would e.g. be to reboot a in instance from 'default' into 'all' or 'production' mode.
When the cluster has been configured for a mod_jk frontend, this action would also need to update the worker properties on the apache and enable mod_jk use in embedded tomcat.
If JGroups channels use TCP with listing the cluster IPs for discovery, this would also mean to update the existing configs with the IP of the new node.
The idea behind copying a config is to load it via ConfigurationFacet from the template node and write / update it via ConfigurationFacet to the new nodes. An alternative could be to copy over the files that contain the configuration.
We need to be careful with stuff we detect on the template node that we don't know and probably copy this over literally.
1.2.2 Remove node
We need to be able to remove a node. This can e.g. be done by setting the partion name to some unused (/invalid) value and also at least changing the MC-IP to some unused value too. It is better to shut the server down

Here, the user first selects a cluster in the left pane and the system then shows the available nodes in this cluster. The user can then remove one or more nodes from the cluster. Do we want to allow to delete all nodes, effectively deleting the complete cluster?
For mod_jk and JGropus in TCP mode, the additions from 1.2.1 need to be reversed too.
When removing a node, we should make sure that the node is no longer used:
- Modify mod_jk to no longer route requests to it
- See if we can get JBossCache / JGroups to no longer do work over it and detect if all running work has been done (i.e. all Tx are commited)
- Change the configuration of the node.
1.3 Change cluster props
Basic properties of a cluster configuration consist of JBossCache params: multicast-ip, port, partition name. Those need to be changeable in any case.
I think it is valid to assume that all JGroups channels share the same partition name all over the cluster.

Here the user first selects a cluster and the system shows the existing props. The user can edit them. After clicking assign, the change is propagated to all cluster nodes and all JGroups channels of the cluster.
TODO: find out how to distinguish between different JGroups channels (i.e. every channel must have a different triple partition/ip/port) - is it enough to just start with a start port and increase it by 1 per channel? Channels also need a different partition name, so the partition name shown in the UI sketch above should only be a common suffix tha gets prepended a prexif unique to a channel. The multicast address may be the same across all channels. Looks like this gets easier in AS5
TODO : UI needs also needs the possibility to assign a bind address for cluster traffic - on a per node base.
Many clustering configurations use system property substitution (i.e. ${jboss.partition.name:Default}), where the real partition name is passed in via run.sh script. This would mean that we'd need to modify the startup scripts - do we want this?
1.4 Create cluster from scratch
This is sort of a special case of 1.2.1 + 1.3 as we would start with a field to enter a new cluster name, present the properties and then add selected AS servers with those properties to the new cluster.
Creating a cluster from scratch will require an existing fully cluster aware node that will function as a template.
As an alternative (extended version), we use a fully cluster aware node to copy its configuration into our database as template and can apply this template to any new node without having this template server available. This would allow to have different template configurations (and even to supply some by JBoss when delivering JBossON This is not feasible, due to the many different base configurations out there)
1.5 Assign / change buddy group
On larger clusters it is a good idea to have AS instances being in buddy groups. We need to assist creating groups and assigning AS instances to such groups. Technically the relation is not 1:0..1 for AS and buddy group, as an AS has n caches and each cache can be in a different buddy group. We should probably for the start not allow this flexibility, but make it a 1:0..1 relation.
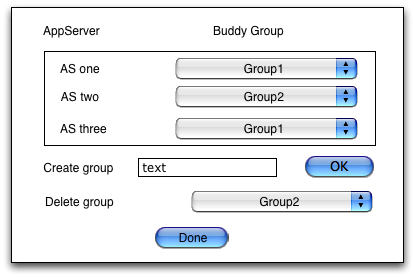
Next to assigning AS instances to a group, it must be possible to create a group (that can be used for assignment) and to delete a group (where all the AS instances in it get put into the 'default' unassigned group). It is also necessary to specify with how many buddies to replicate state with.
1.6 Make .war clusterable
War files that are to be used in a cluster need to have the <distributable/> property set. Jopr should be able to do this if the administrator wants it do do it.
2 Tomcat/JBossWeb
This section lists stuff we need to do for (embedded) Tomcat / JBossWeb
2.1 Enable jk
Users that use Tomcat often use Apache in front of Tomcats.
In order to use a loadbalancer in front of Tomcat, it needs to create additional node information in the jsessionid. In jboss-web.deployer/META-INF/jboss-service.xml (this is no longer needed in AS 5):
<attribute name="UseJK">true<attribute>
In addition it is necessary to add JvmRoute to the AJP/13 engine in server.xml :
<Engine name="jboss.web" jmvRoute="Node1">...</..>
2.2 Session Replication
Tomcat uses JBoss Cache and JGroups as replication provider. We need to at least be able to set the default set of params here (REPL_SYNC / REPL_ASYNC , buddy replication enabled, region-based-marshalling on/off).
Snapshot mode and intervals should not be exposed to the GUI See also below
3 JBossAS
This section lists topics in JBossAS that need tweaking / support for clustering
Two caches are standard in 4.2+, all configuration, that could need special treatment over 'generic' caches that the user deploys.
Those are
jboss.cache:service=EJB3SFSBClusteredCache
jboss.cache:service=TomcatClusteringCache
Those should be marked. And perhaps get an own UI, that only shows the service bits that the user is to modify and hides the JGroups /JBC details.
3.1 EJB3
3.1.1 cluster-service.xml
3.1.2 Enable HA JNDI
3.1.3 EJB2
3.1.4 Other
We still need to find out / decide how to handle configurations that are hidden within a xAR deployed by the user. JBoss deployer allow to hide .SAr within .EAR files, which both can be zipped.
3.2 Deploy on all nodes
JBoss offers the farm service for deployment on multiple cluster nodes. But this is not stable on all versions on JBossAS. So we need to be able to deploy applications on all nodes.
The default here is that the new application gets deployed through Jopr and not as an individual deploy on one server (basically like we do this for single nodes now).
3.2.1 Copy over existing apps
When taking a new node into a cluster, it is also required to distribute existing applications. This must not happen blindly, but we should give
the user the choice
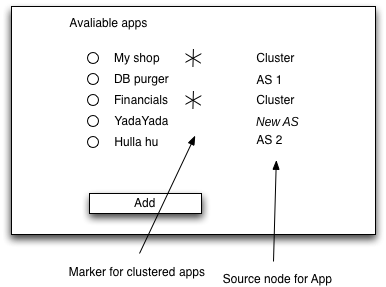
So when the user has selected the cluster and the new node, we show him a list of applications from all nodes together with the information if they are already clustered (i.e. existing in >1 node) and the source node. He can then select those he wants to cluster and they get distributed accordingly.
3.3 HA-JMS
This needs to be adjusted when making changes to HA-JNDI
We should also be able to adjust the Datasources from the GUI here (but actually that applies for simple JMS too) See also
4 JBoss Cache
A very big part of JBoss clustering relies on JBoss Cache and the underlying JGroups infrastructue. It is planned for AS 5, that JBoss Cache is the only inter-node communication mechanism. Thus we need very strong support of JBossCache and JGroups
The following shows an excerpt of a JBossCache config page in Jopr
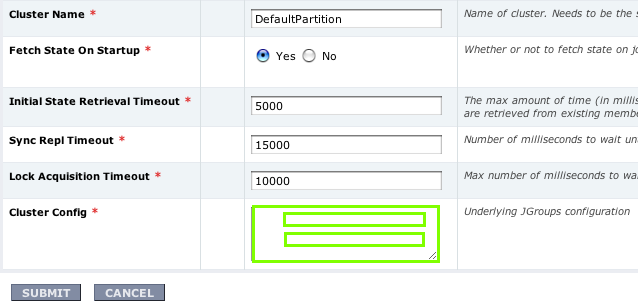
The cluster config section (marked in green) needs to be replaced by a JGroups-config editor.
We still need to find out if do this inline as shown here, or if we have JGroups as a sub-service
* Subservice is easier for the GUI and plugin, but needs knowledge about the 'embedding' JBossCache
* Embedded is more natural to people that usually edit a JBossCache config with its embedded JGroups config.
4.1 JGroups
The communication with other JBossCache nodes runs over JGroups. So to be able to work on clustering, we need a strong JGroups plugin as its foundation. It must be possible to change the existing stack.
http://www.jgroups.org/javagroupsnew/docs/manual/html_single/index.html#protlist lists the whole building blocks of the JGroups stack. As there are too many options, we should probably restrict ourselves to the most common/important ones ( -> discuss with JGroups team) and transparently read/write the others, that are not shown to the user (this is good practice anyway, as the user is free to enter his own protocol elements in the stack, which we can't know anyways). As an alternative, we can also just present all attributes that we find on an existing config to the user and allow him to enter new attributes as he wants.
4.1.0 How to present the JGroups channels/Cache instances of a cluster to the user?
To edit JGroups channels, we'd first present a gui screen to select the cluster to work on on the left:
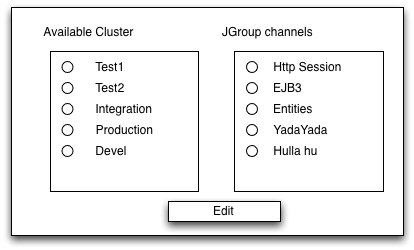
Then when the user has selected the cluster, we present the channel / chache on the right. When the user has selected an item to work, he clicks edit and gets to the real editor screen (as above and in the next section).
4.1.1 UI Editor (extension ?)
To support this, we need perhaps an UI editor extension, that is able to parse the JGroups XML snipped embedded in a JBossCache configuration and to present entries for each of the JGroup stack elements.
While it is possible to have a JGroups config for JBossCache in an external file, it is important to support the one which is embedded in a JBossCache configuration.
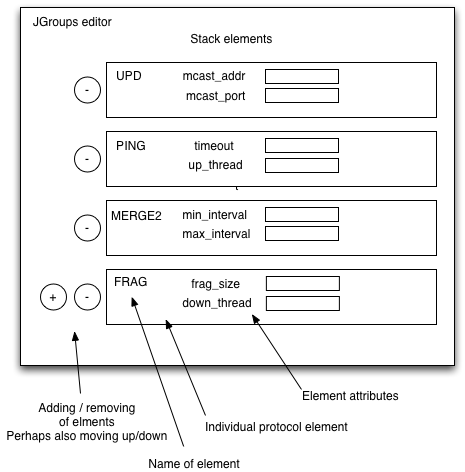
This is a sketch of a JGroups editor. It is important to be able to add and remove (comment out) individual stack elements. As some elements can be in different ordering, giving different semantics, we also need to allow to move them up/down. Insertion between existing elements must be possible.
Bela told me, that he does not see the need to write stack from scratch and that we should start with templates (see below), in which some protocols can be disabled and for which we allow to change the parameters of the protocol (as shown in the editor sketch). He also does not see the need for reordering of elements (even if it is possible in some limited way).
Another use case (for the future) would be to automatically have a UDP based stack be converted in a TCP based one
Ian told me, that this editor could be possible (sans reordering) with the actual UI when each stack element is a map within a list of stack element maps.
Reordering could be done by inserting an 'order' column where the user puts the actual order. Advantage is that this can be done with the existing UI. Disadvantage is that if you have a stack with 5 elements and you want to insert something in position 2, you have to change the order entry of 4 elements (we could by default, when presenting the config to the user use numbers 10,20,... leaving enough space for insertion).
4.1.2 Templates
We need to support templates of JGroups stacks for the most common application use cases (wan usage, lan usage, with and without multicast).
Those templates would only need to be filled with some needed params:
4.1.3 Params
The following are standard params that need to be different for JGroups channels (and for different clusters too).
UDP Port
The UDP port where data is sent to
Multicast-IP
Partition Name
Partition name of this cluster.
4.1.4 JGroups MBeans
JGroups exports since AS 4.2.2 (in the 'all' configuration), version "JGroups 2.4.1 SP-4", its channel information via Mbeans:

Those allow for limited configuration, but can serve to read statistics about the intra-node traffic, which can be important in a cluster.
5. Events
Topology changes need to trigger events on the cluster (pseudo-)resource (not the individual AS / JBC / HAPartiton level).
This information is/can be used to feed into a "Topology change" portlet on the dashboard.
Note: JBossCache and HAPartition have different APIs to get at this information.
6. Monitoring
Monitoring should provide cluster average values and the possibility to detect cluster nodes that run outside the average (sort of cluster baselines).
This probably needs to include the individual weight factors for the cluster nodes from the mod_jk setup.
The system should be able to automatically monitor the intra-cluster traffic and show outliers / have alerts on them - would rely on some group level alerts.
Cluster loads above a certain limit should trigger the start of a cold standby cluster member.
7. Inventory
We need a cluster inventory view, that is not only keyed by cluster, but also by application meaning, that one can click on an application and see all cluster(s) this is deployed.
8. Open Questions
* How will RHQ make the association between a cluster of JBossAS (cluster of compatible resources) with the frontend apache, that comes from a different resource type hierarchy?
* What mechanism can we use to copy over applications? Load them on the server and push them to the other agent? Have agents talk peer to peer?
Agent to agent has the big disadvantage of the need to more ports and holes in the firewall.
Many of the cluster operations would need 2-phase-commit semantics.
* Implementation
Plugins normally only supply the agent part of functionality plus meta data used by agent and server.
In the case of above use cases, we often need workflows (that could be run by jBPM), that need GUI support too. As the workflow and the UI elements are specific to JBossAS clustering (could perhaps be used by some other AS clustering like AS5 or ...), we need to decide how and where the UI elements plus the workflow component is hosted. The workflow is not necessarily limited to one agent, as a cluster usually spans more than one machine.
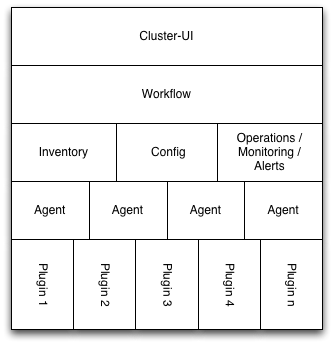
This new UI + Workflow could be deployed as additional server plugin.
We could also decide to add server side plugin functionality to each plugin, that gets wired via additional meta data in the plugin descriptor. As the clustering functionality encompases more then one plugin and the workflow sits on top of them, it probably does not help a lot here.
Comments