This article discusses a few questionable design decissions in jBPM, what consequences they have in terms of usage and limitations that derive from it. Specifically it addresses these issues
- A jBPM client cannot start a process without prior knowledge of the specific process runtime behaviour
- A jBPM client cannot interact with a process without prior knowledge of the exact process structure
- The concept of parallel paths of excecution is not sufficiently supported
- Process state is not associated with process structure. The approach of a global data bucket does not isolate data sufficiently.
- A Process deployment is insuffiently isolated from other process deployments
After describing the issues in greater detail, the article moves on to discuss possible solutions to these problems. The goal is to come to a common understanding of what is conceptualy correct and what an API should look like that allows a jBPM client to interact with the jBPM engine and individual Processes in the most appropriate way.
Existing possible design flaws
This section present possible design flaws in the existing jBPM code base.
Starting a process and borrowing the client thread
Lets consider a very simple process. A StartEvent followed by a Task followed by an EndEvent. A possible client to this process could be a unit test, a web application, an enterprise service bus (ESB), etc ...

The possible API that the client would interact with could look like this
ProcessDefinition pd = ProcessDefinition.create(pdXML); Process p = pd.newInstance(); p.start(); // blocking call
TaskA is expected to complete in a short amount of time, 'p.start()' is blocking call and returns after the generated Token reaches the EndEvent - all good.
In case TaskA is a long running ScriptTask and design is such that 'p.start()' is indeed a blocking call, the client thread would hang for the amount of time it takes for TaskA to complete (e.g. 1.5h) - which is of course not acceptable for most clients. Clients of this simplistic API would be forced to work around this threading issue themseleves, which might not be trivial considering timeout issues, premature process termination, error handling, etc
A possible solution is that 'p.start()' is not a blocking call. It is more like a start signal that returns immediately.
ProcessDefinition pd = ProcessDefinition.create(pdXML); Process p = pd.newInstance(); p.start(); p.wait(timeout); // blocking call
This approach does not borrow the client thread. Instead the ProcessEngine deals with all the issues mentioned above. An obvious consequence is that control is returned immediately to the client when the process has been started. The client would need to interact with the process in another way (i.e. through Signals, Messages, Callback Handlers, etc ...)
Client / Process interaction at wait states
In jBPM there is the notion of 'wait state', it essentially means that:
- The Process borrows the client thread
- The Process continous execution until it reaches a wait state that requires client interaction
- The Process returns control to the client that started it
- The client provides the required data and signals the Process to continue along a specific path
In the process below, lets assume that TaskA is a short running JavaTask and TaskB is a UserTask that represents a wait state.

With the current jBPM API that would not be a problem. If TaskA is not a short running JavaTask however,the same API cannot be used. The issue is the same as above and a direct consequence of the "borrowing the client thread" problem.
The general problem of client interaction in the way described above is, that it binds client code to the intimate details of the process definition. The client needs to know if the following task is long or short running because it will have to take care of the threading issues itself. Also, if there are more than one possible paths to take the client must signal explicitly - again needing to have knowledge over the process definition. If another path is added to the process definition clients inevitably break that do not consider the additional path.
The decission which path to take should be data driven and be an integral part of the process definition where possible. Forcing this knowledge on the client effectivly makes the client an extension of the process. It needs to implement the functionality of a complex gateway that is not part of the process definition.
jBPM does not provide an API that allows flawless client/process interaction for processes with long running automated tasks followed by tasks that require user interaction.
No support for parallel paths of execution
jBPM does not have the notion of parallel execution because the ProcessEngine does not deal with threading. If a design explicitly sais that execution paths should happen in parallel, which is expressed here by the usage of a parallel gateway, the ProcessEngine should be able to account for that requirement.
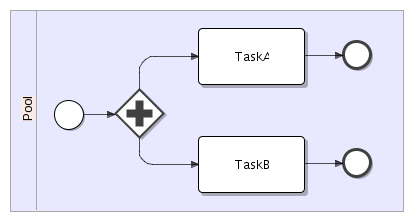
Currently a jBPM client cannot interact with the process above if both TaskA and TaskB are long running script tasks that do not require user interaction and are expected to execute in parallel. Also note, that TaskA and TaskB may represent arbitarily complex paths of execution that are not limmited to a single Task.
Conceptually correct would be an implementation that performs some sort of scheduling.
Stateless Process results in global data bucket
Lets assume TaskA and TaskB are simple counter Nodes that internally hold the count of tokens that have passed through. Another example is that implementation of an Exclusive Gateway used as a join. The semantics of the construct is that it ignores all incomming tokens except the first one. To do this it must maintain some state, which is different from other Exclusive Gateways in the same Process. There are many other examples that can be used to show that at least conceptually stateful Nodes are required - here I only named a few.
Currently, a jBPM Process is stateless. All state is held in a global data bucket called 'Execution'. Access to individual data items is not isolated. Read and write access is permitted from every Node. In Java this is equivalent to a programming model where objects do not have properties and every method takes a hashmap parameter that contains the entire execution state.
Conceptual correct would be that Nodes can hold private data that is not visible by other Nodes. The Process itself should be stateful.
Insuficient isolation of deployment artefacts
Currently jBPM uses a single ProcessEngine instance in a given target container. It relies on Hibernate to do its persistence work. The hibernate session is loaded lazily when accessed the first time.
A process archive (par) is deployed via the jBPM console and does not use the JBoss deployer architecture. From this questions arrise like
- Should a par not be simply be dropped into/removed from the deploy folder?
- What is the scope of classes that come with the par?
- What is the scope of database configurations (i.e. hibernate mapping)?
- What is the scope of engine configuration?
At a conceptual level process deployments need to be isolated from each other. This does not only include tha actual Process Definition but also configuration, user provided Java classes, and other artefacts.
Possible Solutions
This section provides possible solutions to the problems above.
Starting a process is always an asynchronous operation
Executing a process should be seen as a unit of work, which is decoupled from the client that starts the process. Starting a process is always asynchronous, and does not take place in the transactional context of the client. The API does however provide means for the client to wait for the process to terminate and obtain a result from it. Based on the process result the client may commit or rollback its own transaction.
A possible API would look like this
ProcessDefinition pd = ProcessDefinition.create(pdXML);
Process p = pd.newInstance();
clientTx.start();
try
{
// start the process asynchronously
p.startProcess();
// wait for the process to terminate
p.wait(timeout);
if (p.getStatus() != Status.COMPLETED)
throw new RuntimeException("client rollback");
clientTx.commit();
}
catch (RuntimeException rte)
{
clientTx.rollback();
}
Client / Process interaction using Messages and Callbacks
Because the client always starts the process asynchronously, there is no way that the Process temporarily returns control to the client thread that started it. This is conceptually correct because the client should indeed not take part in Process execution. Instead the ProcessDefinition defines how the process is executed. The API must however provide a means for the client to exchange data with the Process, or influence process execution in certain ways.
Key is that the Process at the lowest API level uses Signals and Messages to communicate with its environment. A Signal is like a flare shot up into the air that anybodywho notices it can react upon. A Message is a directed form of communication that has a specific receiver.
When the Process runs into a Node that requires user data (i.e. a UserTask), a Message containing the current Process execution data (i.e. the data from the Token) is sent to the user. The Token that caused the Message is suspended. When the user is done, it sends back a Message to the Process. The Token is reactivated and the data from the Message is copied to the Token before it continous to the next Node.
The client can choose to interact with the MessageService directly, which would require to setup a MessageListener, receive, process, and send the Message using low level API calls. The API should also provide the notion of Callback, which would make it more convenient for the client to receive/provide data from/to the Process. The Process calls the client when required, not visa versa.
A possible API would look like this
ProcessDefinition pd = ProcessDefinition.create(pdXML);
Process p = pd.newInstance();
p.registerCallback("UserTask", new MyCallback());
p.startProcess();
p.wait(timeout);
class MyCallback implements Callback
{
void execute(ProcessControll pc)
{
Data in = pc.getData();
if(validate(in) == false)
{
pc.cancelToken();
}
else
{
Data out = doStuff(in);
pc.setData(out);
}
}
}
The use Messages as a means of communication with the Process is especially valid if one considers jBPM / ESB integration. The ESB isself (for very good reasons) is based on a Message API.The Process can be started asynchronously from an ESB Action (without borrowing the ESB thread). Arbitrary ESB Actions act as Message receivers/senders. Threading and transaction handling is implementation detail of the ProcessEngine.
Support for parallel paths of execution
Whether parallel paths of execution should be supported or not should be based on whether it is conceptually required or not. Forcing a single threaded model results in ProcessDefinitions and client code that need to "work around" this limitation, which would otherwise be modelled in a much more natual way.
For the discussion of parallel paths of execution I will not show an API, because it is ultimately an implementation detail of the underlying ProcessEngine. I can however share the ideas on a conceptual level based on work that I have done to implement parallel paths of execution.
Conceptually it could be such that the ProcessDefinition is an immutable, persistent, stateful entity. A client creates a new Process instance from the ProcessDefinition that is a mutable, persistent, stateful entity.
ProcessDefinition pd = ProcessDefinition.create(pdXML);
Object fooValue = pd.getProperty("foo");
Process p = pd.newInstance();
p.setProperty("foo", getVariationOf(fooValue));
p.getNode("SomeNode").setProperty("foo", getSomeNodeProperty());
The state associated with a given Process is not visible from another Process that is based on the same ProcessDefinition.
An arbitary number of Tokens move each independent of the other through the Process. A Token is a conceptual union of data and a pointer to the Node where it is currently located. Executing a Node, which includes the optional execution of java extensions (i.e. the associated Activity) and moving the Token to the next Node is an atomic operation. A Token can be active or suspended. Suspended Tokens do not take part on scheduling, if Java threads are used they are not associated with a running thread. Suspending a Token ends the current transaction. Whether this should happen implicitly or represents an error condition remains to be dicussed.
The Process terminates when there are no more running Tokens in the Process.
Data separation in Stateful Process and Token
As already described above, the Process instance should be a mutable, persistent, stateful entity. Conceptually, each Node can hold arbitrary state that is isolated from the state of other Nodes. Ultimately a Node implementation should be indepenent and self suficient defining its required input data set, implementation and output data set (e.g. a CreditCard operation Node). These Nodes should be usable as independent building blocks and not need to care about data isolation themselves. Moreover, core building blocks that need to maintain state (i.e. Gateway, ReceiveTask, etc) should be able to persist that state independent of the state associated with the Token state.
When the Process is started the client may provide data that is used to construct the initial Token
ProcessDefinition pd = ProcessDefinition.create(pdXML); Process p = pd.newInstance(); p.startProcess(initialData);
A Token is also a mutable, persistent, stateful entity. It holds state independent of the state in other Tokens. When a Token is canceled its state is discarded. When Tokens from parallel paths are merged, their state is merged as well.
Isolation of deployment artefacts
Using the jBPM console as a receiver of process deployments does not leverage the JBoss deployment architecture. As a result Process deployments are not sufficiently isolated.
Process deployment should conceptually be handled like a web-app deployment to the Servlet container. jBPM should also support hot-deployment of Processes in containers that support it (i.e. JBoss, Tomcat). In a standalone environment, the API that the client uses to deploy a Process and its associated artefacts should not be different to the API that a JBoss deployer uses to do the same.
The API for Process deployment could conceptually look like this
ProcessDeployment dep = new ProcessDeployment(pdXML); dep.setClassLoader(urlLoader); dep.addAttachment(moreStuff); engine.getService(DeploymentService.class).deploy(dep);
Important among other considerations is, that deployments are isolated from each other.
Conclusion
To conclude here a few requirements that I have for jBPM4
- Client can start a Process without prior knowledge of its runtime behaviour
- Process communicates with environment through Signals and Messages
- ProcessEngine does not force the concurrency consideration on the client
- Data is sufficiently isolated between the various entities that are involved during Process execution
- Support for a deployment model that is suitable for a J2EE environment
Feedback is of course very welcome
-thomas
Comments